2. 开发基础 #
本章帮助用户熟悉K230软件开发的基础底层工具,对K230_SDK和nncase进行简单介绍,帮助用户熟悉SDK环境搭建、镜像编译烧录、kmodel转换的过程。
2.1 K230 SDK#
2.1.1. K230 SDK 简介#
K230 SDK 是面向K230 开发板的软件开发包,包含了基于Linux&RT-smart 双核异构系统开发需要用到的源代码,工具链和其他相关资源。源码地址:kendryte/k230_sdk: (github.com) 或 kendryte/k230_sdk: (gitee.com)。

K230 SDK软件架构层次如图所示:
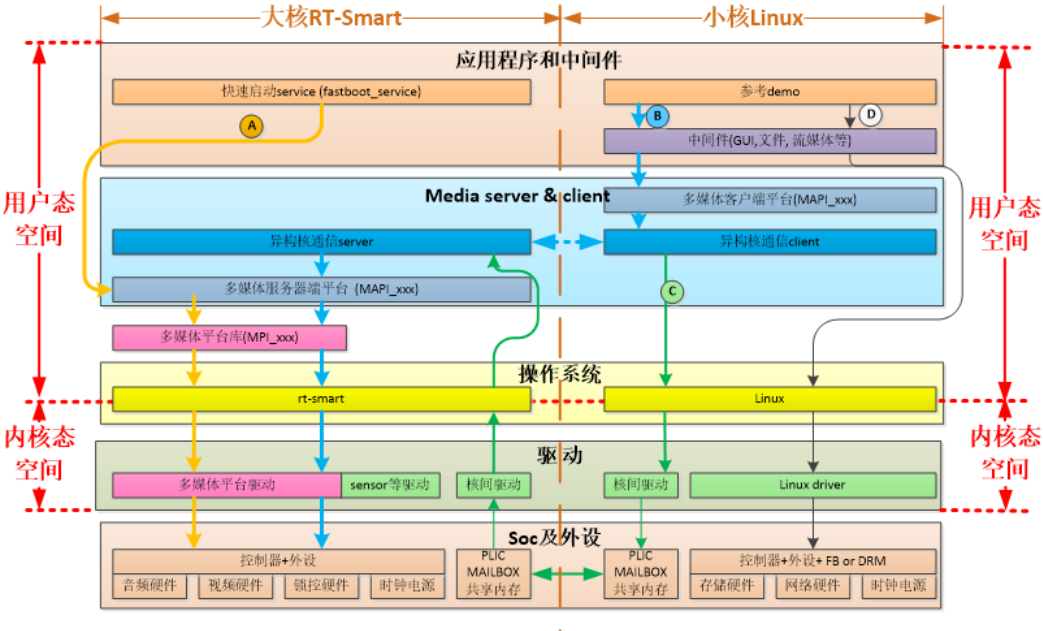
2.1.2. 配置软件开发环境#
K230 SDK需要在Linux环境下编译,推荐使用Ubuntu Linux 20.04。
如需使用windows环境编译,建议使用WSL2 + Docker环境。
获取docker编译镜像 推荐在docker环境中编译K230 SDK,可直接使用如下docker镜像:
docker pull ghcr.io/kendryte/k230_sdk
可使用如下命令确认docker镜像拉取成功:
docker images | grep k230_sdk
说明: docker镜像中默认不包含toolchain,下载源码后,使用命令’make prepare_sourcecode’会自动下载toolchain至当前编译目录中。
如果不使用docker编译环境,而是希望使用原生Linux进行编译,可参考tools/docker/Dockerfile,安装相应的工具至您的Linux系统中即可。
如下载速度较慢或无法成功,可使用tools/docker/Dockerfile自行编译docker image,详情请参考K230 SDK使用说明: (github.com) 或 K230 SDK使用说明: (gitee.com)
2.1.3. 编译K230 SDK #
2.1.3.1. 下载K230 SDK源码#
git clone https://github.com/kendryte/k230_sdk
# 或执行git clone https://gitee.com/kendryte/k230_sdk.git
cd k230_sdk
make prepare_sourcecode
make prepare_sourcecode会自动下载Linux和RT-Smart toolchain, buildroot package, AI package等. 请确保该命令执行成功并没有Error产生,下载时间和速度以实际网速为准。
2.1.3.2. Linux+RT-Smart双系统镜像编译#
以docker镜像编译为例:
确认当前目录为
k230_sdk源码根目录,使用如下命令进入docker
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
make CONF=k230_canmv_defconfig
编译产物在k230_canmv_defconfig/images中:
k230_canmv_defconfig/images
├── big-core
├── little-core
├── sysimage-sdcard.img # SD和emmc非安全启动镜像
└── sysimage-sdcard.img.gz # SD和emmc的非安全启动镜像压缩包
TF卡和eMMC均可使用
sysimage-sdcard.img镜像,或使用sysimage-sdcard.img.gz解压缩得到该文件。
2.1.3.3 纯RT-Smart单系统镜像编译#
以docker镜像编译为例:
确认当前目录为
k230_sdk源码根目录,使用如下命令进入docker
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
make CONF=k230_canmv_only_rtt_defconfig
编译产物在k230_canmv_only_rtt_defconfig/images中:
k230_canmv_only_rtt_defconfig/images
├── big-core
├── sysimage-sdcard.img # SD和emmc非安全启动镜像
└── sysimage-sdcard.img.gz # SD和emmc的非安全启动镜像压缩包
TF卡和eMMC均可使用
sysimage-sdcard.img镜像,或使用sysimage-sdcard.img.gz解压缩得到该文件。
2.1.3.4. 预编译镜像下载#
如果不希望自行编译镜像,可下载预编译镜像,直接烧录使用
main branch: Github默认分支,作为release分支,编译release镜像自动发布至Release页面.(从
v1.4版本开始支持)预编译release镜像:请访问嘉楠开发者社区, 然后在
K230/Images分类中,下载所需的镜像文件,evb设备下载k230_evb*.img.gz,canmv设备下载k230_canmv*.img.gz。开发者社区仅支持Linux+RT-Smart双系统镜像下载,纯RT-Smart单系统镜像请按照上述步骤自行编译。
下载的镜像默认为
.gz压缩格式,需先解压缩,然后再烧录。 K230 micropython: (github.com)和K230 micropython: (gitee.com)镜像所支持的功能与K230 SDK并不相同。
2.1.3.5. 镜像烧录#
Linux:
在TF卡插到宿主机之前,输入:
ls -l /dev/sd\*
查看当前的存储设备。
将TF卡插入宿主机后,再次输入:
ls -l /dev/sd\*
查看此时的存储设备,新增加的就是TF卡设备节点。
假设/dev/sdc就是TF卡设备节点,执行如下命令烧录TF卡:
sudo dd if=sysimage-sdcard.img of=/dev/sdc bs=1M oflag=sync
Windows:
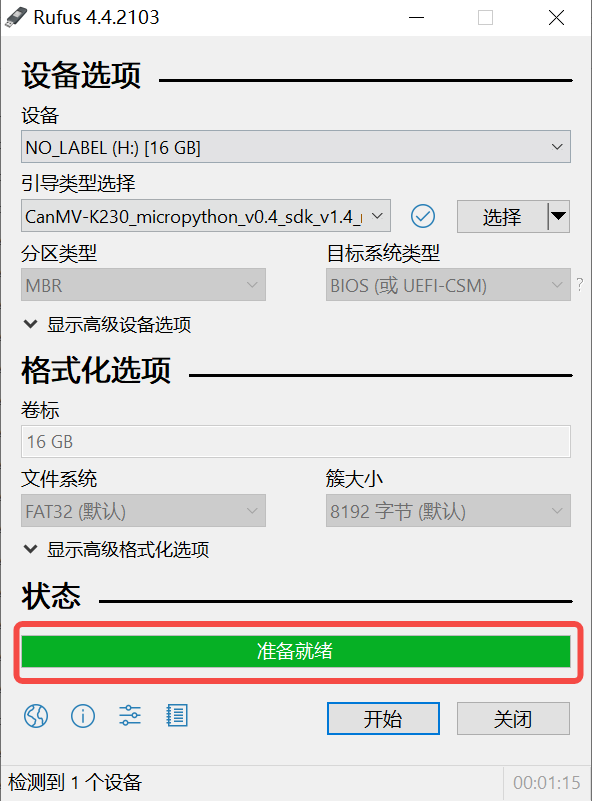
Windows下可通过rufus工具对TF卡进行烧录,rufus工具下载地址。
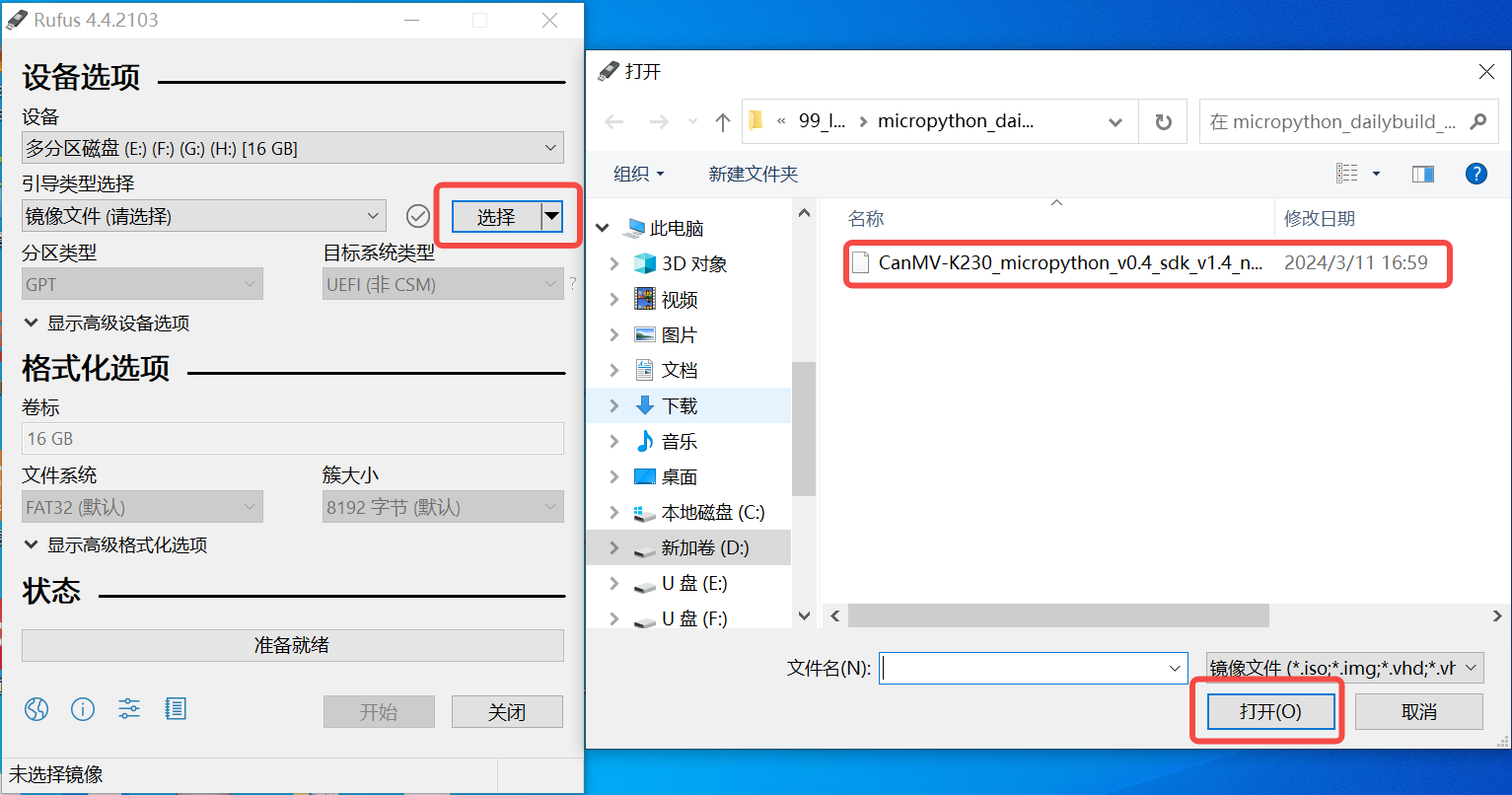
1)将TF卡插入PC,然后启动rufus工具,点击工具界面的”选择”按钮,选择待烧写的固件。
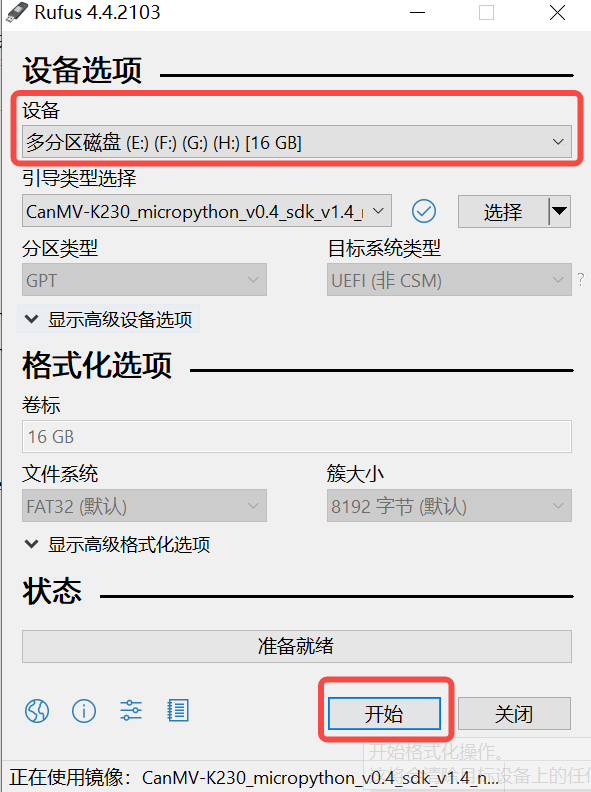
2)点击“开始”按钮开始烧写,烧写过程有进度条展示,烧写结束后会提示“准备就绪”。
2.2. nncase简介#
2.2.1. nncase介绍#
nncase是面向 AI 加速器的神经网络编译器,用于为 Kendryte系列芯片生成推理所需要的模型文件 .kmodel,并提供模型推理所需要的 runtime lib。
本教程主要包括以下内容:
使用
nncase完成模型编译,生成kmodel。在PC和开发板上执行
kmodel推理。
2.2.2. 模型编译和模拟器推理#
2.2.2.1. 安装nncase工具链#
nncase工具链包括 nncase和 nncase-kpu插件包,两者均需正确安装才可以编译出CanMV-K230所支持的模型文件。nncase和 nncase-kpu插件包均在nncase github release发布,并且依赖dotnet-7.0。
Linux平台可以直接使用pip进行nncase和nncase-kpu插件包在线安装,Ubuntu环境下可使用apt安装dotnet。pip install --upgrade pip pip install nncase pip install nncase-kpu # nncase-2.x need dotnet-7 sudo apt-get update sudo apt-get install -y dotnet-sdk-7.0
Tips:如果使用官方提供的CanMV镜像,必须检查SDK中nncase的版本和使用pip安装的nncase版本是否一致。
Windows平台仅支持nncase在线安装,nncase-kpu需要在nncase github release手动下载安装。用户若没有Ubuntu环境, 可使用
nncase docker(Ubuntu 20.04 + Python 3.8 + dotnet-7.0)cd /path/to/nncase_sdk docker pull ghcr.io/kendryte/k230_sdk docker run -it --rm -v `pwd`:/mnt -w /mnt ghcr.io/kendryte/k230_sdk /bin/bash -c "/ bin/bash"
Tips:目前仅支持py3.6-3.10,如果pip安装失败请检查pip对应的Python版本。
2.2.2.2. 环境配置#
使用pip安装软件包后,需将安装路径添加到PATH环境变量中。
export PATH=$PATH:/path/to/python/site-packages/
2.2.2.3. 原始模型说明#
nncase目前支持 tflite、onnx格式的模型,更多格式的支持还在进行中。
Tips:
对于TensorFlow的
pb模型,请参考官方文档将其转换为tflite格式。注意不要设置量化选项,直接输出浮点模型即可。如果模型中存在quantize和dequantize算子,则属于量化模型,目前不支持。对于PyTorch的
pth等格式模型,需使用torch.export.onnx接口导出onnx格式。
2.2.2.4. 编译参数说明#
进行模型编译前,您需要了解以下关键信息:
KPU推理使用定点运算。因此在编译模型时,必须配置量化相关参数,用于将模型从浮点转换为定点。详见nncase文档中的PTQTensorOptions说明。nncase支持将前处理层集成到模型中,这可以减少推理时的前处理开销。相关参数和示意图见nncase文档的CompileOptions部分。
2.2.2.5. 编译脚本说明#
本Jupyter notebook:(github.com)或Jupyter notebook:(gitee.com)分步骤详细描述了使用nncase编译、推理kmodel的流程,notebook内容涵盖:
参数配置:介绍如何正确配置编译参数,以满足实际部署需求;
获取模型信息:说明从原始模型中获取网络结构、层信息等关键数据的方法;
设置校正集数据:阐述如何准备好校正集样本数据,包括单输入和多输入模型两种情况,以用于量化校准过程;
设置推理数据格式:讲解推理部署时如何配置输入数据,支持不同需求场景;
配置多输入模型:介绍处理多输入模型时,如何正确设置每个输入的形状、数据格式等信息;
PC模拟器推理:说明如何在PC上利用模拟器推理
kmodel,这是验证编译效果的关键步骤;比较推理结果:通过与不同框架(TensorFlow、PyTorch等)的推理结果比较,验证kmodel的正确性;
以上步骤系统地介绍了模型编译的全流程,既适合初学者从零开始学习,也可作为经验丰富用户的参考指南。