我使用了
_thread.start_new_thread(fun1,())
_thread.start_new_thread(fun2,())
第一个线程是目标检测任务,第二个线程是播放.wav文件,运行结果是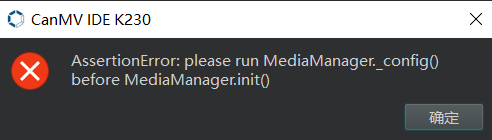
目标检测任务正常执行,但是没有播放.wav文件,如果调换顺序执行
_thread.start_new_thread(fun2,())
_thread.start_new_thread(fun1,())
则不会报错,但是目标检测任务没有正常进行,只有摄像头的画面显示在IDE缓冲区,.wav文件也没有播放
如何在进行目标检测任务的时候播放.wav文件?
Viewed 366

2 Answers
请给出代码,如果目标检测使用的是aidemo的模式,MediaManager的init被封装在了PipeLine中,如果需要同时播放音频和运行人脸检测,需要重新调整代码结构,在MediaManager.init之前配置好视频和音频的配置,然后再执行MediaManager.init。
========================24/11/11===============================
这里给出示例的代码:
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
from media.pyaudio import * # 音频模块
from media.media import * # 软件抽象模块,主要封装媒体数据链路以及媒体缓冲区
import media.wave as wave # wav音频处理模块
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aicube
import _thread
audio_run=True
# 自定义目标检测任务类
class DetectionApp(AIBase):
def __init__(self,kmodel_path,labels,model_input_size=[640,640],anchors=[10.13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326],model_type="AnchorBaseDet",confidence_threshold=0.5,nms_threshold=0.25,nms_option=False,strides=[8,16,32],rgb888p_size=[1280,720],display_size=[1920,1080],debug_mode=0):
super().__init__(kmodel_path,model_input_size,rgb888p_size,debug_mode)
# kmodel路径
self.kmodel_path=kmodel_path
# 类别标签
self.labels=labels
# 模型输入分辨率
self.model_input_size=model_input_size
# 检测任务的锚框
self.anchors=anchors
# 模型类型,支持"AnchorBaseDet","AnchorFreeDet","GFLDet"三种模型
self.model_type=model_type
# 检测框类别置信度阈值
self.confidence_threshold=confidence_threshold
# 检测框NMS筛选阈值
self.nms_threshold=nms_threshold
# NMS选项,如果为True做类间NMS,如果为False做类内NMS
self.nms_option=nms_option
# 输出特征图的降采样倍数
self.strides=strides
# sensor给到AI的图像分辨率,宽16字节对齐
self.rgb888p_size=[ALIGN_UP(rgb888p_size[0],16),rgb888p_size[1]]
# 视频输出VO分辨率,宽16字节对齐
self.display_size=[ALIGN_UP(display_size[0],16),display_size[1]]
# 调试模式
self.debug_mode=debug_mode
# 检测框预置颜色值
self.color_four=[(255, 220, 20, 60), (255, 119, 11, 32), (255, 0, 0, 142), (255, 0, 0, 230),
(255, 106, 0, 228), (255, 0, 60, 100), (255, 0, 80, 100), (255, 0, 0, 70),
(255, 0, 0, 192), (255, 250, 170, 30), (255, 100, 170, 30), (255, 220, 220, 0),
(255, 175, 116, 175), (255, 250, 0, 30), (255, 165, 42, 42), (255, 255, 77, 255),
(255, 0, 226, 252), (255, 182, 182, 255), (255, 0, 82, 0), (255, 120, 166, 157)]
# Ai2d实例,用于实现模型预处理
self.ai2d=Ai2d(debug_mode)
# 设置Ai2d的输入输出格式和类型
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT,nn.ai2d_format.NCHW_FMT,np.uint8, np.uint8)
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self,input_image_size=None):
with ScopedTiming("set preprocess config",self.debug_mode > 0):
# 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,您可以通过设置input_image_size自行修改输入尺寸
ai2d_input_size=input_image_size if input_image_size else self.rgb888p_size
# 计算padding参数
top,bottom,left,right=self.get_padding_param()
# 配置padding预处理
self.ai2d.pad([0,0,0,0,top,bottom,left,right], 0, [114,114,114])
# 配置resize预处理
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel)
# build预处理过程,参数为输入tensor的shape和输出tensor的shape
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]])
# 自定义当前任务的后处理,这里调用了aicube模块的后处理接口
def postprocess(self,results):
with ScopedTiming("postprocess",self.debug_mode > 0):
# AnchorBaseDet模型的后处理
if self.model_type == "AnchorBaseDet":
det_boxes = aicube.anchorbasedet_post_process( results[0], results[1], results[2], self.model_input_size, self.rgb888p_size, self.strides, len(labels), self.confidence_threshold, self.nms_threshold, self.anchors, self.nms_option)
# GFLDet模型的后处理
elif self.model_type == "GFLDet":
det_boxes = aicube.gfldet_post_process( results[0], results[1], results[2], self.model_input_size, self.rgb888p_size, self.strides, len(labels), self.confidence_threshold, self.nms_threshold, self.nms_option)
# AnchorFreeDet模型的后处理
elif self.model_type=="AnchorFreeDet":
det_boxes = aicube.anchorfreedet_post_process( results[0], results[1], results[2], self.model_input_size, self.rgb888p_size, self.strides, len(labels), self.confidence_threshold, self.nms_threshold, self.nms_option)
else:
det_boxes=None
return det_boxes
# 将结果绘制到屏幕上
def draw_result(self,pl,det_boxes):
with ScopedTiming("draw osd",self.debug_mode > 0):
if det_boxes:
pl.osd_img.clear()
for det_boxe in det_boxes:
# 获取每一个检测框的坐标,并将其从原图分辨率坐标转换到屏幕分辨率坐标,将框和类别信息绘制在屏幕上
x1, y1, x2, y2 = det_boxe[2],det_boxe[3],det_boxe[4],det_boxe[5]
sx=int(x1 * self.display_size[0] // self.rgb888p_size[0])
sy=int(y1 * self.display_size[1] // self.rgb888p_size[1])
w = int(float(x2 - x1) * self.display_size[0] // self.rgb888p_size[0])
h = int(float(y2 - y1) * self.display_size[1] // self.rgb888p_size[1])
pl.osd_img.draw_rectangle(sx , sy , w , h , color=self.get_color(det_boxe[0]))
label = self.labels[det_boxe[0]]
score = str(round(det_boxe[1],2))
pl.osd_img.draw_string_advanced(sx, sy-50,32, label + " " + score , color=self.get_color(det_boxe[0]))
else:
pl.osd_img.clear()
pl.osd_img.draw_rectangle(0, 0, 128, 128, color=(0,0,0,0))
# 计算padding参数
def get_padding_param(self):
ratiow = float(self.model_input_size[0]) / self.rgb888p_size[0];
ratioh = float(self.model_input_size[1]) / self.rgb888p_size[1];
ratio = min(ratiow, ratioh)
new_w = int(ratio * self.rgb888p_size[0])
new_h = int(ratio * self.rgb888p_size[1])
dw = float(self.model_input_size[0]- new_w) / 2
dh = float(self.model_input_size[1] - new_h) / 2
top = int(round(dh - 0.1))
bottom = int(round(dh + 0.1))
left = int(round(dw - 0.1))
right = int(round(dw - 0.1))
return top,bottom,left,right
# 根据当前类别索引获取框的颜色
def get_color(self, x):
idx=x%len(self.color_four)
return self.color_four[idx]
def audio_output_thread(output_stream):
CHUNK = int(0.3 * 16000) # 每次读取音频数据的帧数,设置为0.3s的帧数16000*0.3=4800
reply_wav_file = "/sdcard/examples/utils/wozai.wav" # 音频路径
while audio_run:
wf = wave.open(reply_wav_file, "rb")
wav_data = wf.read_frames(CHUNK)
while wav_data:
output_stream.write(wav_data)
wav_data = wf.read_frames(CHUNK)
time.sleep(1) # 时间缓冲,用于播放回复声音
wf.close()
if __name__=="__main__":
# 其它参数
THRESH = 0.5 # 检测阈值
SAMPLE_RATE = 16000 # 采样率16000Hz,即每秒采样16000次
CHANNELS = 1 # 通道数 1为单声道,2为立体声
FORMAT = paInt16 # 音频输入输出格式 paInt16
CHUNK = int(0.3 * 16000) # 每次读取音频数据的帧数,设置为0.3s的帧数16000*0.3=4800
# 初始化音频流
p = PyAudio()
p.initialize(CHUNK)
# 添加显示模式,支持"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# kmodel路径
kmodel_path="/sdcard/examples/ai_test_kmodel/insect_det.kmodel"
# 检测类别标签
labels=["leconte","boerner","armandi","linnaeus","coleoptera","acuminatus"]
# 类别置信度阈值
confidence_threshold=0.5
# nms阈值
nms_threshold = 0.5
# 训练中使用的锚框,在线训练平台和AICube部署包的deploy_config.json文件中包含该字段,只有AnchorBaseDet需要该参数
anchors=[30,23,21,33,29,43,44,29,41,39,41,68,71,43,59,61,71,72]
# 初始化PipeLine,只关注传给AI的图像分辨率,显示的分辨率
pl=PipeLine(rgb888p_size=[1280,720],display_size=display_size,display_mode=display_mode)
pl.create()
# 用于播放回复音频
output_stream = p.open(format=FORMAT,channels=CHANNELS,rate=SAMPLE_RATE,output=True,frames_per_buffer=CHUNK)
_thread.start_new_thread(audio_output_thread,(output_stream,))
# 检测类实例,关注模型输入分辨率,传给AI的图像分辨率,显示的分辨率
det=DetectionApp(kmodel_path,labels,model_input_size=[640,640],anchors=anchors,rgb888p_size=[1280,720],display_size=display_size,debug_mode=0)
# 配置预处理过程
det.config_preprocess()
try:
while True:
os.exitpoint()
with ScopedTiming("total",1):
# 获取当前帧
img=pl.get_frame()
# 获得检测框
det_boxes=det.run(img)
# 绘制检测框和类别信息
det.draw_result(pl,det_boxes)
# 显示当前的绘制结果
pl.show_image()
gc.collect()
except BaseException as e:
sys.print_exception(e)
audio_run=False
finally:
audio_run=False
time.sleep(1)
output_stream.stop_stream()
output_stream.close()
det.deinit()
pl.destroy()
