2. Development Basics#
This chapter helps users become familiar with the foundational tools for K230 software development. It provides a brief introduction to K230_SDK and nncase, aiding users in setting up the SDK environment, compiling and flashing images, and converting kmodel.
2.1 K230 SDK#
2.1.1. Introduction to K230 SDK#
K230 SDK is a software development kit for the K230 development board. It includes source code, toolchains, and other related resources necessary for developing on the Linux & RT-smart dual-core heterogeneous system. Source code can be found at: kendryte/k230_sdk: (github.com) or kendryte/k230_sdk: (gitee.com).

The software architecture of K230 SDK is shown in the diagram below:
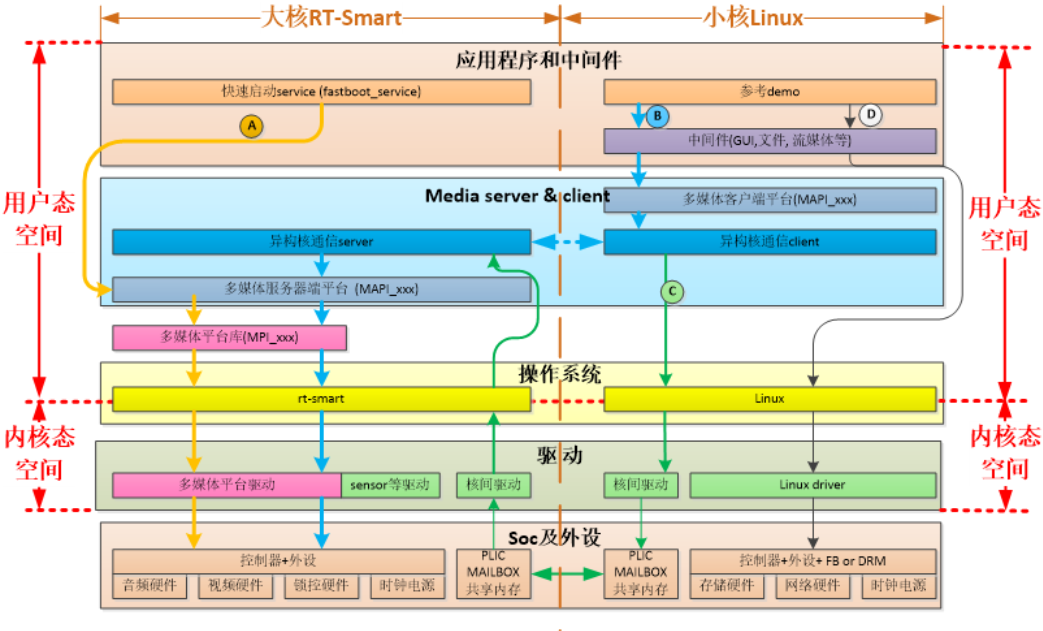
2.1.2. Setting Up the Software Development Environment#
K230 SDK needs to be compiled in a Linux environment, with Ubuntu Linux 20.04 being recommended.
If you need to use a Windows environment for compilation, it is recommended to use WSL2 + Docker.
To obtain the Docker compilation image, it is recommended to compile the K230 SDK within a Docker environment. You can directly use the following Docker image:
docker pull ghcr.io/kendryte/k230_sdk
You can verify the successful pull of the Docker image with the following command:
docker images | grep k230_sdk
Note: The Docker image does not include the toolchain by default. After downloading the source code, use the command
make prepare_sourcecodeto automatically download the toolchain to the current compilation directory.
If you prefer not to use the Docker compilation environment and want to compile using native Linux, you can refer to tools/docker/Dockerfile to install the corresponding tools on your Linux system.
If the download speed is slow or unsuccessful, you can compile the Docker image yourself using tools/docker/Dockerfile. For more details, refer to K230 SDK User Guide: (github.com) or K230 SDK User Guide: (gitee.com).
2.1.3. Compiling K230 SDK #
2.1.3.1. Downloading K230 SDK Source Code#
git clone https://github.com/kendryte/k230_sdk
# Or execute git clone https://gitee.com/kendryte/k230_sdk.git
cd k230_sdk
make prepare_sourcecode
make prepare_sourcecodewill automatically download the Linux and RT-Smart toolchains, buildroot package, AI package, etc. Ensure that this command executes successfully without errors. The download time and speed depend on your actual network conditions.
2.1.3.2. Compile Linux+RT-Smart dual system image#
Using the Docker image for compilation as an example:
Ensure the current directory is the root directory of the
k230_sdksource code.Enter Docker using the following command:
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
make CONF=k230_canmv_defconfig
The compiled products are in k230_canmv_defconfig/images:
k230_evb_defconfig/images
├── big-core
├── little-core
├── sysimage-sdcard.img # Non-secure boot image for SD and emmc
└── sysimage-sdcard.img.gz # Compressed non-secure boot image for SD and emmc
Both TF cards and eMMC can use the
sysimage-sdcard.imgimage, or usesysimage-sdcard.img.gzto extract this file.
2.1.3.3. Compile a pure RT-Smart single system image#
Using the Docker image for compilation as an example:
Ensure the current directory is the root directory of the
k230_sdksource code.Enter Docker using the following command:
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
make CONF=k230_canmv_only_rtt_defconfig
The compiled products are in k230_canmv_defconfig/images:
k230_evb_defconfig/images
├── big-core
├── sysimage-sdcard.img # Non-secure boot image for SD and emmc
└── sysimage-sdcard.img.gz # Compressed non-secure boot image for SD and emmc
Both TF cards and eMMC can use the
sysimage-sdcard.imgimage, or usesysimage-sdcard.img.gzto extract this file.
2.1.3.4. Precompiled Image Download#
If you do not wish to compile the image yourself, you can download precompiled images for direct use.
main branch: The default branch on GitHub, used as the release branch. Compiled release images are automatically published to the Release page. (Supported from
v1.4version onwards)Precompiled release images: Visit Canaan Developer Community and download the required image files under the
K230/Imagescategory. Downloadk230_evb*.img.gzforevbdevices andk230_canmv*.img.gzforcanmvdevices.The developer community only supports the download of Linux+RT-Smart dual-system image. For pure RT-Smart single-system image, please compile it yourself according to the above steps.
The downloaded images are in
.gzcompressed format. Decompress them before flashing. The images for K230 micropython: (github.com) and K230 micropython: (gitee.com) do not support the same features as the K230 SDK.
2.1.3.5. Flashing the Image#
Linux:
Before inserting the TF card into the host machine, input:
ls -l /dev/sd\*
Check the current storage devices.
After inserting the TF card into the host machine, input again:
ls -l /dev/sd\*
Check the storage devices again. The newly added one is the TF card device node.
Assuming /dev/sdc is the TF card device node, execute the following command to flash the TF card:
sudo dd if=sysimage-sdcard.img of=/dev/sdc bs=1M oflag=sync
Windows:
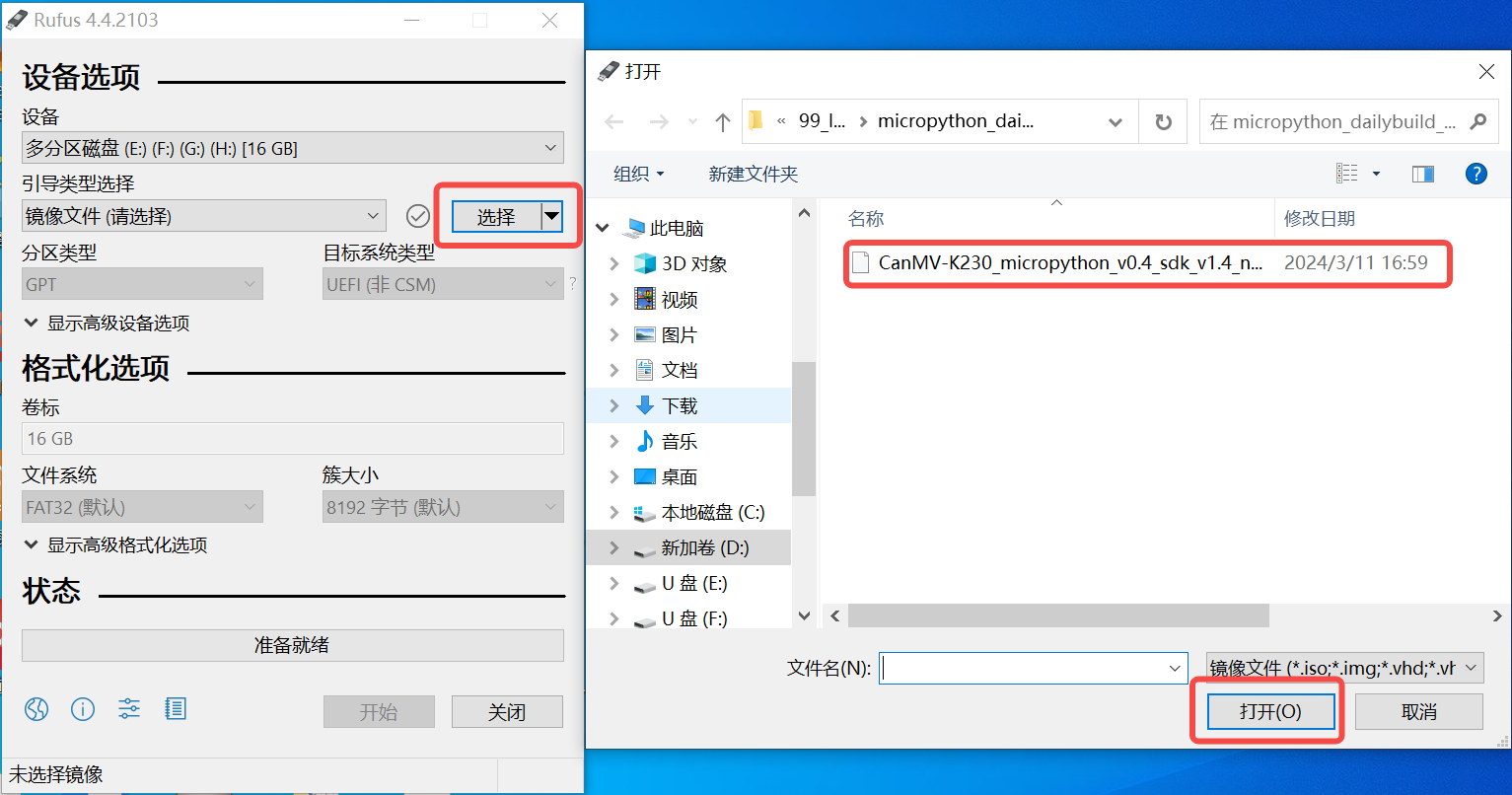
On Windows, you can use the Rufus tool to flash the TF card. Rufus tool download link.
Insert the TF card into the PC, then start the Rufus tool. Click the “Select” button on the tool interface and choose the firmware to be flashed.
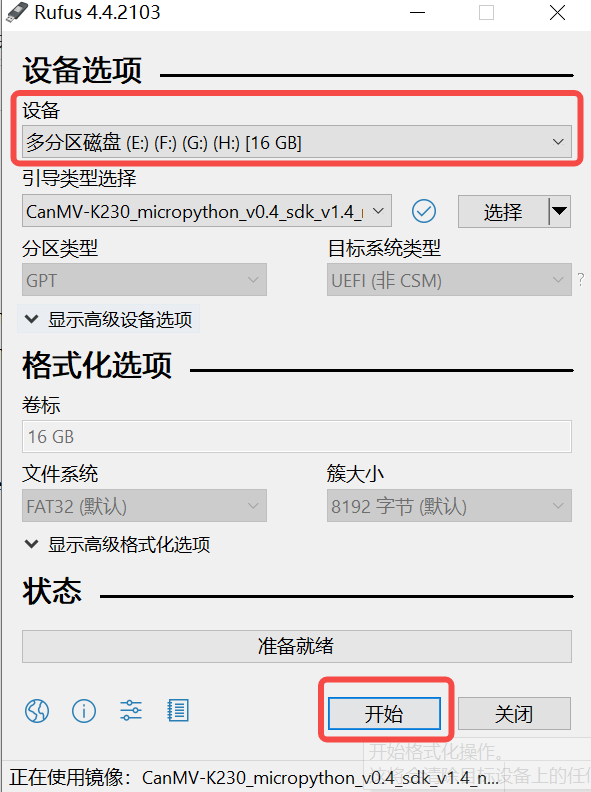
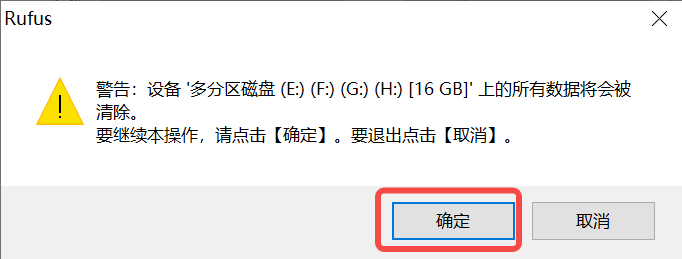
Click the “Start” button to begin flashing. The flashing process will show a progress bar, and it will indicate “Ready” when finished.
2.2. Introduction to nncase#
2.2.1. Overview of nncase#
nncase is a neural network compiler for AI accelerators, used to generate inference-required model files .kmodel for the Kendryte series chips, and provides the runtime lib needed for model inference.
This tutorial mainly covers the following contents:
Using
nncaseto complete model compilation and generatekmodel.Executing
kmodelinference on both PC and development boards.
2.2.2. Model Compilation and Simulator Inference#
2.2.2.1. Installing the nncase Toolchain#
The nncase toolchain includes the nncase and nncase-kpu plugin packages. Both must be correctly installed to compile model files supported by CanMV-K230. nncase and nncase-kpu plugin packages are released on nncase GitHub release and depend on dotnet-7.0.
On the
Linuxplatform, you can directly use pip to installnncaseandnncase-kpuplugin packages online. On Ubuntu, you can useaptto installdotnet.pip install --upgrade pip pip install nncase pip install nncase-kpu # nncase-2.x needs dotnet-7 sudo apt-get update sudo apt-get install -y dotnet-sdk-7.0
Tips: If using the CanMV image provided by the official source, ensure that the nncase version in the SDK matches the version installed via pip.
On the
Windowsplatform, onlynncasesupports online installation.nncase-kpuneeds to be manually downloaded and installed from nncase GitHub release.If you do not have an Ubuntu environment, you can use
nncase docker(Ubuntu 20.04 + Python 3.8 + dotnet-7.0).cd /path/to/nncase_sdk docker pull ghcr.io/kendryte/k230_sdk docker run -it --rm -v `pwd`:/mnt -w /mnt ghcr.io/kendryte/k230_sdk /bin/bash -c "/bin/bash"
Tips: Currently, only py3.6-3.10 is supported. If pip installation fails, check the Python version corresponding to pip.
2.2.2.2. Environment Configuration#
After installing the software packages with pip, add the installation path to the PATH environment variable.
export PATH=$PATH:/path/to/python/site-packages/
2.2.2.3. Original Model Description#
nncase currently supports models in tflite and onnx formats. Support for more formats is in progress.
Tips:
For TensorFlow
pbmodels, refer to the official documentation to convert them totfliteformat. Ensure that you do not set quantization options and directly output the floating-point model. If the model contains quantize and dequantize operators, it is a quantized model, which is currently not supported.For PyTorch models in
pthand other formats, use thetorch.export.onnxinterface to export the model inonnxformat.
2.2.2.4. Compilation Parameters Description#
Before compiling the model, you need to understand the following key information:
KPUinference uses fixed-point arithmetic. Therefore, when compiling the model, you must configure quantization-related parameters to convert the model from floating-point to fixed-point. See thenncasedocumentation for details on PTQTensorOptions.nncasesupports integrating the preprocessing layer into the model, which can reduce preprocessing overhead during inference. Relevant parameters and diagrams can be found in thenncasedocumentation under CompileOptions.
2.2.2.5. Compilation Script Description#
This Jupyter notebook: (github.com) or Jupyter notebook: (gitee.com) provides a step-by-step detailed description of the process of using nncase to compile and infer kmodel. The notebook covers:
Parameter Configuration: Introduces how to correctly configure compilation parameters to meet actual deployment needs.
Obtaining Model Information: Explains how to extract key data such as network structure and layer information from the original model.
Setting Calibration Dataset: Describes how to prepare calibration dataset samples, including both single-input and multi-input models, for the quantization calibration process.
Setting Inference Data Format: Discusses how to configure input data during inference deployment to support different scenarios.
Configuring Multi-Input Models: Introduces how to correctly set the shape, data format, and other information for each input in multi-input models.
PC Simulator Inference: Explains how to use the simulator to infer
kmodelon a PC, which is a key step to verify the compilation results.Comparing Inference Results: Verifies the correctness of
kmodelby comparing inference results with different frameworks (TensorFlow, PyTorch, etc.).
These steps systematically introduce the entire model compilation process, suitable for both beginners starting from scratch and experienced users as a reference guide.