10. Source Code Level Application Development#
Note:
This chapter uses SDK version 1.1.0 and nncase version 2.4.0 for implementation. For future updates, please refer to: kendryte/K230_training_scripts (github.com).
Pay attention to version compatibility during development. For the corresponding relationship between k230_sdk versions and nncase versions, refer to: K230 SDK nncase Version Compatibility — K230 Documentation (canaan-creative.com).
For related tutorial videos, see the reference chapter links.
This chapter introduces the usage of the KTS (k230_training_scripts) tool and the process of model deployment on the board. KTS provides source code for four tasks—classification, detection, translation, and keyword wake-up—from training to deployment, covering multiple modalities such as CV, NLP, and speech. The source code is visible to the user, and interested users can modify the source code to change datasets, models, etc. This tool is suitable for users with a mature understanding of deep learning tasks in different modalities and who wish to deploy them using the k230 development board.
10.1 Using KTS for Image Classification Tasks#
The k230_training_scripts (KTS) provide detailed source code-level k230 development cases, covering AI tasks related to CV, NLP, and audio. The GitHub address for KTS is: kendryte/K230_training_scripts (github.com). Compared to the above two tools, KTS is more flexible and requires higher coding skills from the user. Users can modify configuration steps, change models, adjust parameters, and achieve rapid development and deployment of k230 applications from the source code.
Using KTS for AI development involves several steps: environment setup, data preparation, model training and testing, CANMV k230 image compilation and burning, C++ code compilation, network configuration, and file transfer, and k230-side deployment. Taking a vegetable classification scenario as an example, refer to the code at: kendryte/K230_training_scripts.
10.1.1 Environment Setup#
Linux system;
Install GPU drivers;
Install Anaconda to create a model training environment;
Install Docker to create an SDK image compilation environment;
Install the dotnet SDK;
10.1.2 Data Preparation#
Organize the custom dataset for the image classification task as shown in the following format:
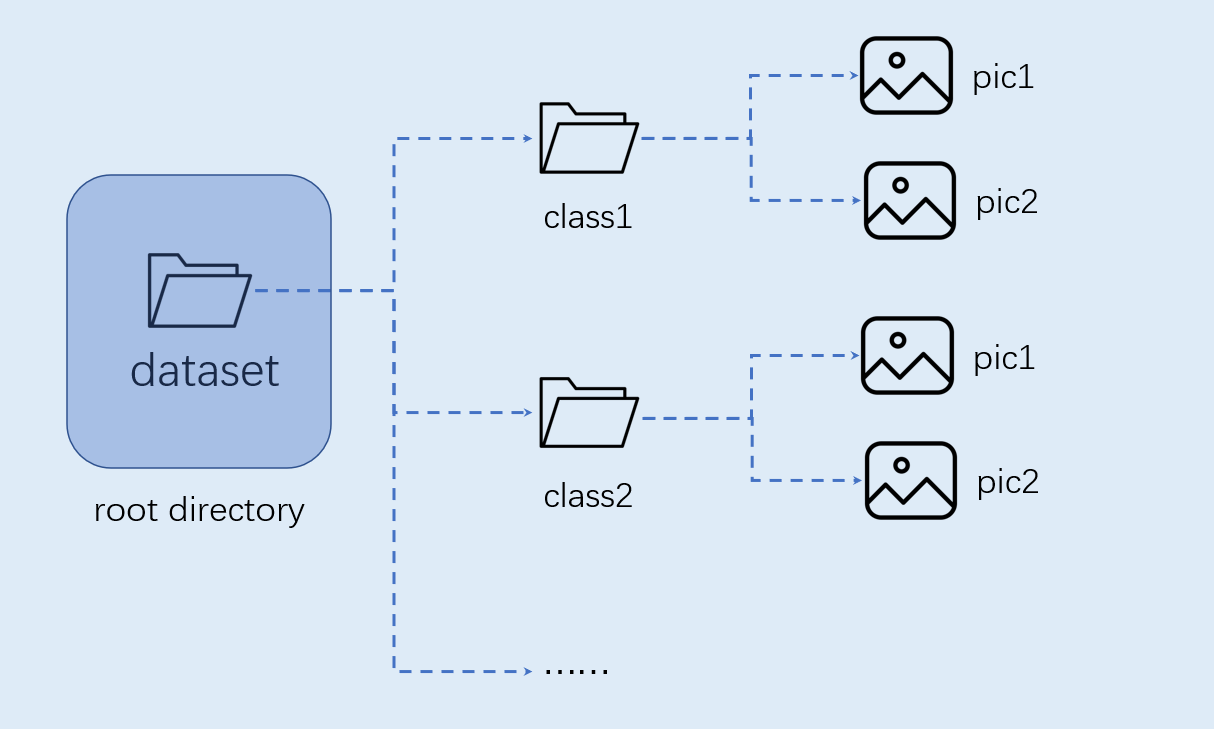
Note: The image classification dataset must be organized in the above format.
10.1.3 Model Training and Testing#
This section is implemented in the training environment.
10.1.3.1 Create a Virtual Environment#
Open the command terminal:
conda create -n myenv python=3.9
conda activate myenv
10.1.3.2 Install Python Dependencies#
Install the Python libraries used for training according to the requirements.txt file in the project, and wait for the installation to complete:
pip install -r requirements.txt
The requirements.txt file will install the model conversion packages nncase and nncase-kpu. nncase is a neural network compiler designed for AI accelerators.
When compiling images and using nncase to convert kmodels, pay attention to the version compatibility. For the corresponding relationship between k230_sdk versions and nncase versions, refer to the following link:
K230 SDK nncase Version Compatibility — K230 Documentation (canaan-creative.com)
You can replace the nncase and nncase-kpu versions according to the corresponding versions, for example, to change the nncase version to 2.7.0:
pip install nncase==2.7.0
pip install nncase-kpu==2.7.0
10.1.3.3 Configure Training Parameters#
The configuration file yaml/config.yaml in the provided training script is set as follows:
dataset:
root_folder: ../data/veg_cls # Path to the classification dataset
split: true # Whether to re-split, must be true for the first run
train_ratio: 0.7 # Training set ratio
val_ratio: 0.15 # Validation set ratio
test_ratio: 0.15 # Test set ratio
train:
device: cuda
txt_path: ../gen # Path for the generated txt files for training, validation, and test sets, label names file, and calibration set file
image_size: [ 224,224 ] # Resolution
mean: [ 0.485, 0.456, 0.406 ]
std: [ 0.229, 0.224, 0.225 ]
epochs: 10
batchsize: 8
learningrate: 0.001
save_path: ../checkpoints # Path to save the model
inference:
mode: image # Inference mode, divided into image and video; in image mode, you can infer a single image or all images in a directory, in video mode, you can infer using the camera
inference_model: best # Divided into best and last, calling best.pth and last.pth under checkpoints respectively for inference
images_path: ../data/veg_cls/bocai # If this path is an image path, single image inference is performed; if it is a directory, inference is performed on all images in the directory
deploy:
chip: k230 # Chip type, divided into "k230" and "cpu"
ptq_option: 0 # Quantization type, 0 is uint8, 1, 2, 3, 4 are different forms of uint16
10.1.3.4 Model Training#
Enter the scripts directory of the project and execute the training code:
python3 main.py
If the training is successful, you can find the trained last.pth, best.pth, best.onnx, and best.kmodel in the model_save_dir directory specified in the configuration file.
10.1.3.5 Model Testing#
Set the inference part of the configuration file, set the test configuration, and execute the test code:
python3 inference.py
10.1.3.6 Prepare Files#
The files needed for the subsequent deployment steps include:
checkpoints/best.kmodel;
gen/labels.txt;
Test image test.jpg;
10.1.4 K230_SDK Image Compilation and Burning#
When compiling images and using nncase to convert kmodels, pay attention to the version compatibility. For the corresponding relationship between k230_sdk versions and nncase versions, refer to the following link:
K230 SDK nncase Version Compatibility — K230 Documentation (canaan-creative.com)
If you choose to use the images provided in the Images section of the Canaan Developer Community (canaan-creative.com), please pay attention to the version compatibility when downloading and burning.
10.1.4.1 Docker Environment Setup#
# Download the docker compilation image
docker pull ghcr.io/kendryte/k230_sdk
# You can use the following command to confirm whether the docker image was successfully pulled
docker images | grep ghcr.io/kendryte/k230_sdk
# Download the SDK source code
git clone https://github.com/kendryte/k230_sdk.git
cd k230_sdk
# Download the toolchain (Linux and RT-Smart toolchain, buildroot package, AI package, etc.)
make prepare_sourcecode
# Create a docker container, $(pwd):$(pwd) maps the current directory to the same directory inside the docker container, and maps the toolchain directory on the system to the /opt/toolchain directory inside the docker container
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
10.1.4.2 Image Compilation#
Please execute the following commands in the k230_sdk root directory according to different system requirements:
# (1)If you choose to compile the Linux+RT-Smart dual system image yourself, execute the following command
make CONF=k230_canmv_defconfig
# (2)If you choose to use the Linux+RT-Smart dual system image downloaded from the developer community, be sure to execute the following command in the k230_sdk root directory to specify the development board type
make mpp
make CONF=k230_canmv_defconfig prepare_memory
# (3)If you choose to compile a pure RT-Smart system image yourself, execute the following command. The developer community has not yet opened the pure RT-Smart image download
make CONF=k230_canmv_only_rtt_defconfig
Please wait patiently for the image to compile successfully.
For Linux+RT-Smart dual system compilation, download the compiled image from k230_sdk root directory/output/k230_canmv_defconfig/images and flash it to the SD card. Refer to Image Flashing for flashing steps:
k230_canmv_defconfig/images ├── big-core ├── little-core ├── sysimage-sdcard.img # SD card boot image └── sysimage-sdcard.img.gz # Compressed SD card boot image
For RT-Smart single system compilation, download the compiled image from k230_sdk root directory/output/k230_canmv_only_rtt_defconfig/images and flash it to the SD card. Refer to Image Flashing for flashing steps:
k230_canmv_defconfig/images ├── big-core ├── sysimage-sdcard.img # SD card boot image └── sysimage-sdcard.img.gz # Compressed SD card boot image
10.1.4.3 Image Burning#
After compilation, you can find the compiled image files in the output/k230_canmv_defconfig/images directory:
k230_canmv_defconfig/images
├── big-core
├── little-core
├── sysimage-sdcard.img # SD card boot image
└── sysimage-sdcard.img.gz # Compressed SD card boot image
CANMV K230 supports the SDCard boot method. For convenience in development, it is recommended to prepare a TF card (Micro SD card).
Linux:
Before inserting the SD card into the host machine, enter:
ls -l /dev/sd\*
to view the current storage devices.
After inserting the TF card into the host machine, enter again:
ls -l /dev/sd\*
to view the storage devices at this time. The newly added device is the TF card device node.
Assuming /dev/sdc is the TF card device node, execute the following command to burn the TF card:
sudo dd if=sysimage-sdcard.img of=/dev/sdc bs=1M oflag=sync
Windows:
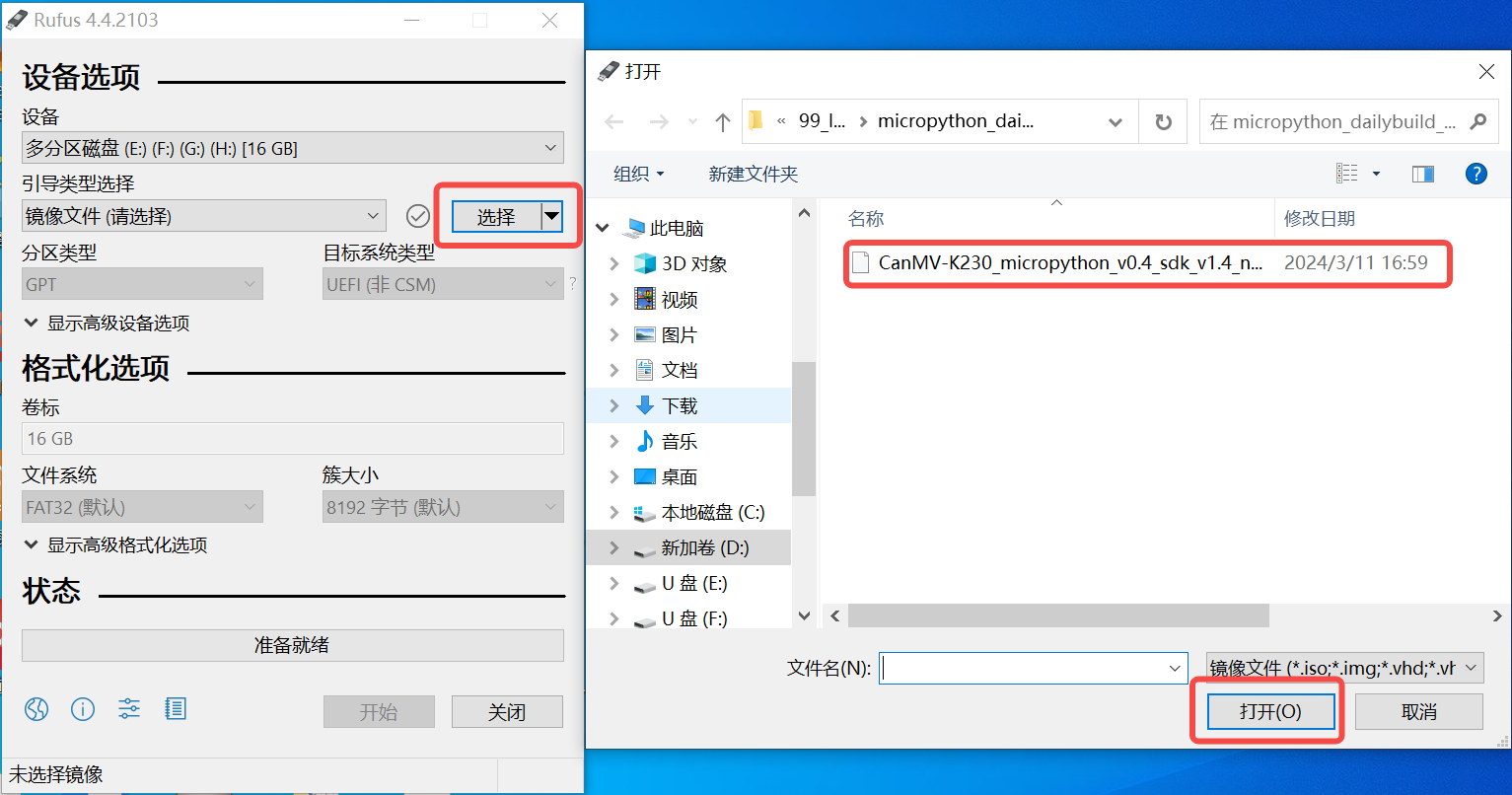
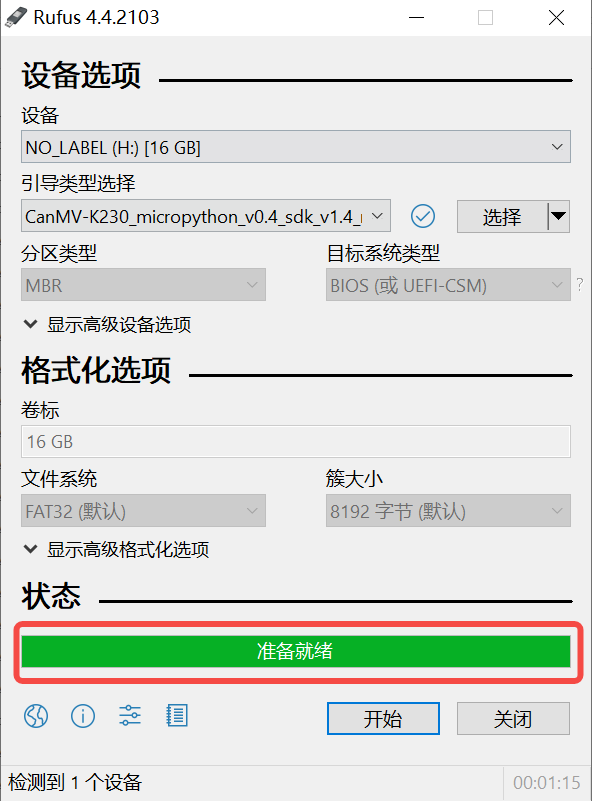
On Windows, you can use the rufus tool to burn the TF card. Download the rufus tool here.
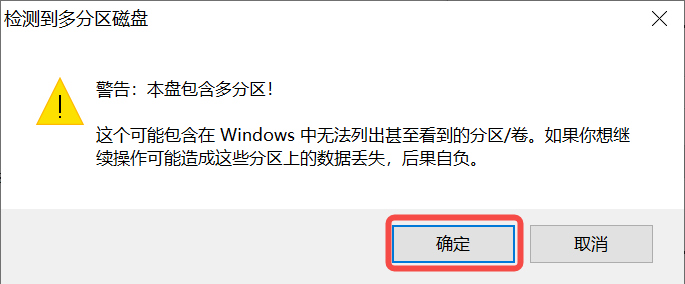
Insert the SD card into the PC, then start the rufus tool, click the “Select” button in the tool interface, and choose the firmware to be burned.
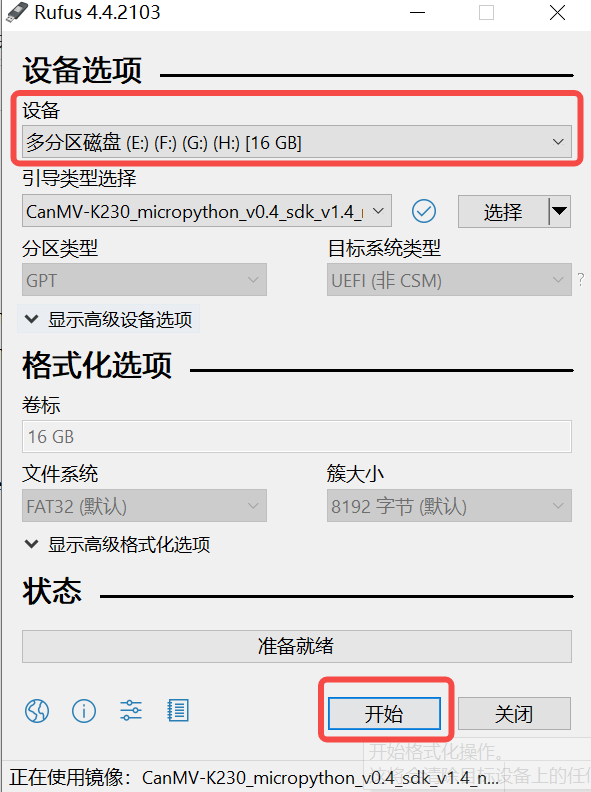
Click the “Start” button to start burning. The burning process has a progress bar display, and after burning is complete, it will prompt “Ready”.
10.1.4.4 Power on the Development Board#
Install MobaXterm for serial communication. Download MobaXterm at: https://mobaxterm.mobatek.net.
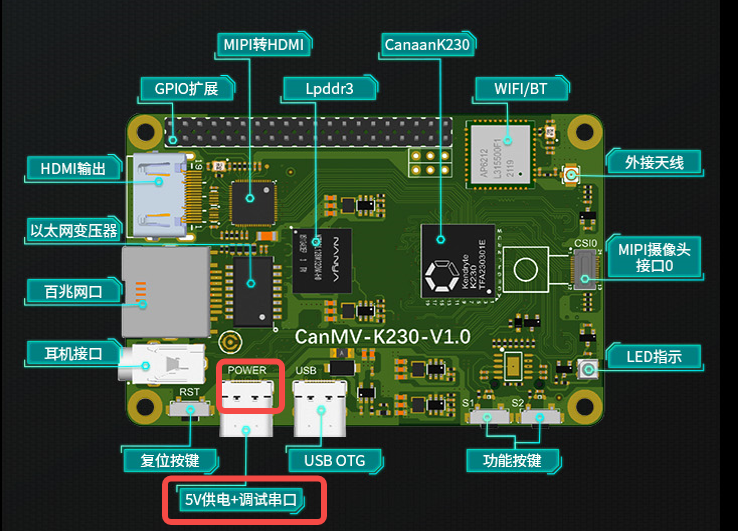
Insert the burned SD card into the board slot, connect HDMI output to the monitor, connect the Ethernet port to the Ethernet, and connect the POWER port to the serial port and power supply.
For Linux+RT-Smart dual system image, after the system is powered on, there will be two serial port devices by default, which can be used to access the small core Linux and large core RT-Smart respectively. The default user name of the small core Linux is root, and the password is empty. When the large core RT-Smart system is powered on, an application will be automatically started, and you can press the q key to exit to the command prompt terminal.
For pure RT-Smart single system image, after the system is powered on, an application will be automatically started in the large-core RT-Smart system when it is turned on. You can press the q key to exit to the command prompt terminal.
10.1.5 C++ Code Compilation#
After completing the preparation of the development board, we can use C++ to write our own code. Below is an example of a related image classification task, along with an analysis of the example code. Refer to the example code at: kendryte/K230_training_scripts.
10.1.5.1 Code Structure#
k230_code
├── cmake
│ ├── link.lds # Link script
│ ├── Riscv64.cmake
├── k230_deploy
│ ├── ai_base.cc # Model deployment base class implementation
│ ├── ai_base.h # Model deployment base class, encapsulates nncase loading, input setting, model inference, and output retrieval operations. Subsequent specific task development only needs to focus on model preprocessing and postprocessing.
│ ├── classification.cc # Image classification code class implementation
│ ├── classification.h # Image classification task class definition, inherits from AIBase, used to encapsulate model inference preprocessing and postprocessing
│ ├── main.cc # Main function, parameter parsing, initialization of the Classification class instance, and implementation of on-board functionality
│ ├── scoped_timing.hpp # Timing tool
│ ├── utils.cc # Utility class implementation
│ ├── utils.h # Utility class, encapsulates common functions for image preprocessing and image classification, including reading binary files, saving images, image processing, result drawing, etc. Users can enrich this file according to their needs.
│ ├── vi_vo.h # Video input-output header file
│ ├── CMakeLists.txt # CMake script for building an executable file using C/C++ source files and linking to various libraries
├── build_app.sh # Compilation script, uses the cross-compilation toolchain to compile the k230_deploy project
└── CMakeLists.txt # CMake script for building the nncase_sdk project
10.1.5.2 Core Code#
Once you have the kmodel model, the specific AI on-board code includes steps such as sensor & display initialization, kmodel loading, model input-output setting, image acquisition, input data loading, input data preprocessing, model inference, model output retrieval, output postprocessing, OSD display, etc. As shown in the diagram:
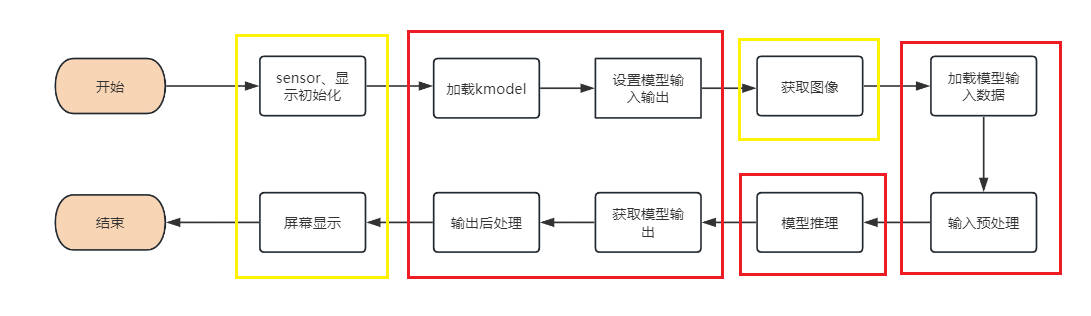
The yellow boxed part in the figure provides interfaces in vi_vo.h. Below, we introduce how to develop AI applications focusing on the red boxed part.
In the above process, kmodel loading, model input setting, model inference, and model output retrieval are common steps for all tasks. We have encapsulated these steps, and ai_base.h and ai_base.cc can be directly copied for use.
ai_base.h defines the AIBase base class and the interfaces for common operations:
#ifndef AI_BASE_H
#define AI_BASE_H
#include <vector>
#include <string>
#include <fstream>
#include <nncase/runtime/interpreter.h>
#include "scoped_timing.hpp"
using std::string;
using std::vector;
using namespace nncase::runtime;
/**
* @brief AI base class encapsulating nncase-related operations
* Mainly encapsulates nncase loading, input setting, running, and output retrieval operations. Subsequent demo development only needs to focus on model preprocessing and postprocessing.
*/
class AIBase
{
public:
/**
* @brief AI base class constructor, loads kmodel and initializes kmodel input and output
* @param kmodel_file Path to the kmodel file
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
AIBase(const char *kmodel_file, const string model_name, const int debug_mode = 1);
/**
* @brief AI base class destructor
* @return None
*/
~AIBase();
/**
* @brief Sets kmodel input
* @param buf Pointer to input data
* @param size Size of input data
* @return None
*/
void set_input(const unsigned char *buf, size_t size);
/**
* @brief Gets kmodel input tensor by index
* @param idx Index of input data
* @return None
*/
runtime_tensor get_input_tensor(size_t idx);
/**
* @brief Sets model input tensor by index
* @param idx Index of input data
* @param tensor Input tensor
*/
void set_input_tensor(size_t idx, runtime_tensor &tensor);
/**
* @brief Initializes kmodel output
* @return None
*/
void set_output();
/**
* @brief Inferences kmodel
* @return None
*/
void run();
/**
* @brief Gets kmodel output, results are stored in the corresponding class attributes
* @return None
*/
void get_output();
protected:
string model_name_; // Model name
int debug_mode_; // Debug mode, 0 (no print), 1 (print time), 2 (print all)
vector<float *> p_outputs_; // List of pointers corresponding to kmodel output
vector<vector<int>> input_shapes_; //{{N,C,H,W},{N,C,H,W}...}
vector<vector<int>> output_shapes_; //{{N,C,H,W},{N,C,H,W}...}} or {{N,C},{N,C}...}} etc.
vector<int> each_input_size_by_byte_; //{0,layer1_length,layer1_length+layer2_length,...}
vector<int> each_output_size_by_byte_; //{0,layer1_length,layer1_length+layer2_length,...}
private:
/**
* @brief Initializes kmodel input for the first time and gets input shape
* @return None
*/
void set_input_init();
/**
* @brief Initializes kmodel output for the first time and gets output shape
* @return None
*/
void set_output_init();
vector<unsigned char> kmodel_vec_; // Stores the entire kmodel data by reading the kmodel file, used for loading kmodel by the kmodel interpreter
interpreter kmodel_interp_; // kmodel interpreter, constructed from the kmodel file, responsible for model loading, input-output setting, and inference
};
#endif
ai_base.cc is the specific implementation of all interfaces defined in ai_base.h.
/*
Specific implementation of AIBase class interfaces defined in ai_base.h
*/
#include "ai_base.h"
#include <iostream>
#include <cassert>
#include "utils.h"
using std::cout;
using std::endl;
using namespace nncase;
using namespace nncase::runtime::detail;
/*AIBase constructor*/
AIBase::AIBase(const char *kmodel_file, const string model_name, const int debug_mode) : debug_mode_(debug_mode), model_name_(model_name)
{
if (debug_mode > 1)
cout << "kmodel_file:" << kmodel_file << endl;
std::ifstream ifs(kmodel_file, std::ios::binary); // Read in kmodel
kmodel_interp_.load_model(ifs).expect("Invalid kmodel"); // kmodel interpreter loads kmodel
set_input_init();
set_output_init();
}
/*Destructor*/
AIBase::~AIBase()
{
}
/*
Initializes kmodel input for the first time
*/
void AIBase::set_input_init()
{
ScopedTiming st(model_name_ + " set_input init", debug_mode_); // Timing
int input_total_size = 0;
each_input_size_by_byte_.push_back(0);
for (int i = 0; i < kmodel_interp_.inputs_size(); ++i)
{
auto desc = kmodel_interp_.input_desc(i); // Input description for index i
auto shape = kmodel_interp_.input_shape(i); // Input shape for index i
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create input tensor"); // Create input tensor
kmodel_interp_.input_tensor(i, tensor).expect("cannot set input tensor"); // Bind tensor to model input
vector<int> in_shape = {shape[0], shape[1], shape[2], shape[3]};
input_shapes_.push_back(in_shape); // Store input shape
int dsize = shape[0] * shape[1] * shape[2] * shape[3]; // Total input bytes
if (debug_mode_ > 1)
cout << "input shape:" << shape[0] << " " << shape[1] << " " << shape[2] << " " << shape[3] << endl;
if (desc.datatype == 0x06) // Input data is of type uint8
{
input_total_size += dsize;
each_input_size_by_byte_.push_back(input_total_size);
}
else if (desc.datatype == 0x0B) // Input data is of type float32
{
input_total_size += (dsize * 4);
each_input_size_by_byte_.push_back(input_total_size);
}
else
assert(("kmodel input data type supports only uint8, float32", 0));
}
each_input_size_by_byte_.push_back(input_total_size); // The last one saves the total size
}
/*
Sets model input data, loads specific input data for the model
*/
void AIBase::set_input(const unsigned char *buf, size_t size)
{
// Check if the input data size matches the model's required size
if (*each_input_size_by_byte_.rbegin() != size)
cout << "set_input: the actual input size{" + std::to_string(size) + "} is different from the model's required input size{" + std::to_string(*each_input_size_by_byte_.rbegin()) + "}" << endl;
assert((*each_input_size_by_byte_.rbegin() == size));
// Timing
ScopedTiming st(model_name_ + " set_input", debug_mode_);
// Loop through model inputs
for (size_t i = 0; i < kmodel_interp_.inputs_size(); ++i)
{
// Get model input description and shape
auto desc = kmodel_interp_.input_desc(i);
auto shape = kmodel_interp_.input_shape(i);
// Create tensor
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create input tensor");
// Map input tensor to writable area
auto mapped_buf = std::move(hrt::map(tensor, map_access_::map_write).unwrap()); // mapped_buf actually has cached data
// Copy data to tensor buffer
memcpy(reinterpret_cast<void *>(mapped_buf.buffer().data()), buf, each_input_size_by_byte_[i + 1] - each_input_size_by_byte_[i]);
// Unmap
auto ret = mapped_buf.unmap();
ret = hrt::sync(tensor, sync_op_t::sync_write_back, true);
if (!ret.is_ok())
{
std::cerr << "hrt::sync failed" << std::endl;
std::abort();
}
// Bind tensor to model input
kmodel_interp_.input_tensor(i, tensor).expect("cannot set input tensor");
}
}
/*
Gets model input tensor by index
*/
runtime_tensor AIBase::get_input_tensor(size_t idx)
{
return kmodel_interp_.input_tensor(idx).expect("cannot get input tensor");
}
/*
Sets model input tensor by index
*/
void AIBase::set_input_tensor(size_t idx, runtime_tensor &tensor)
{
ScopedTiming st(model_name_ + " set_input_tensor", debug_mode_);
kmodel_interp_.input_tensor(idx, tensor).expect("cannot set input tensor");
}
/*
Initializes kmodel output for the first time
*/
void AIBase::set_output_init()
{
// Timing
ScopedTiming st(model_name_ + " set_output_init", debug_mode_);
each_output_size_by_byte_.clear();
int output_total_size = 0;
each_output_size_by_byte_.push_back(0);
// Loop through model outputs
for (size_t i = 0; i < kmodel_interp_.outputs_size(); i++)
{
// Get output description and shape
auto desc = kmodel_interp_.output_desc(i);
auto shape = kmodel_interp_.output_shape(i);
vector<int> out_shape;
int dsize = 1;
for (int j = 0; j < shape.size(); ++j)
{
out_shape.push_back(shape[j]);
dsize *= shape[j];
if (debug_mode_ > 1)
cout << shape[j] << ",";
}
if (debug_mode_ > 1)
cout << endl;
output_shapes_.push_back(out_shape);
// Get total data size
if (desc.datatype == 0x0B)
{
output_total_size += (dsize * 4);
each_output_size_by_byte_.push_back(output_total_size);
}
else
assert(("kmodel output data type supports only float32", 0));
// Create tensor
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create output tensor");
// Bind tensor to model output
kmodel_interp_.output_tensor(i, tensor).expect("cannot set output tensor");
}
}
/*
Sets kmodel output
*/
void AIBase::set_output()
{
ScopedTiming st(model_name_ + " set_output", debug_mode_);
// Loop through and bind output tensors to model outputs
for (size_t i = 0; i < kmodel_interp_.outputs_size(); i++)
{
auto desc = kmodel_interp_.output_desc(i);
auto shape = kmodel_interp_.output_shape(i);
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create output tensor");
kmodel_interp_.output_tensor(i, tensor).expect("cannot set output tensor");
}
}
/*
Calls kmodel_interp_.run() to perform model inference
*/
void AIBase::run()
{
ScopedTiming st(model_name_ + " run", debug_mode_);
kmodel_interp_.run().expect("error occurred in running model");
}
/*
Gets model output (as float pointers, retrieved according to specific postprocessing requirements), preparing for subsequent postprocessing
*/
void AIBase::get_output()
{
ScopedTiming st(model_name_ + " get_output", debug_mode_);
// p_outputs_ stores pointers to model outputs, there can be multiple outputs
p_outputs_.clear();
for (int i = 0; i < kmodel_interp_.outputs_size(); i++)
{
// Get output tensor
auto out = kmodel_interp_.output_tensor(i).expect("cannot get output tensor");
// Map output tensor to host memory
auto buf = out.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_read).unwrap().buffer();
// Convert mapped data to float pointers
float *p_out = reinterpret_cast<float *>(buf.data());
p_outputs_.push_back(p_out);
}
}
Preprocessing and postprocessing vary for different task scenarios, such as using softmax to calculate class probabilities for classification and performing NMS for object detection. Therefore, you can define your task scenario class to inherit from the AIBase class, encapsulating the preprocessing and postprocessing code for that task. Taking image classification as an example:
The Classification class in classification.h inherits from the AIBase class and implements the class definition for the image classification task, mainly defining the interfaces for preprocessing, inference, and postprocessing of the image classification model. The ai2d builder is initialized to perform image preprocessing. It also defines some variables for the image classification task, such as classification threshold, class names, and the number of classes.
#ifndef _CLASSIFICATION_H
#define _CLASSIFICATION_H
#include "utils.h"
#include "ai_base.h"
/**
* @brief Classification task
* Mainly encapsulates the process of preprocessing, running, and postprocessing to get results for each frame of the image
*/
class Classification : public AIBase
{
public:
/**
* @brief Classification constructor, loads kmodel and initializes kmodel input, output, and classification threshold
* @param kmodel_path Path to the kmodel
* @param image_path Path to the inference image (used for static images)
* @param labels List of class names
* @param cls_thresh Classification threshold
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
Classification(string &kmodel_path, string &image_path, std::vector<std::string> labels, float cls_thresh, const int debug_mode);
/**
* @brief Classification constructor, loads kmodel and initializes kmodel input, output, and classification threshold
* @param kmodel_path Path to the kmodel
* @param image_path Path to the inference image (used for static images)
* @param labels List of class names
* @param cls_thresh Classification threshold
* @param isp_shape ISP input size (chw)
* @param vaddr ISP corresponding virtual address
* @param paddr ISP corresponding physical address
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
Classification(string &kmodel_path, string &image_path, std::vector<std::string> labels, float cls_thresh, FrameCHWSize isp_shape, uintptr_t vaddr, uintptr_t paddr, const int debug_mode);
/**
* @brief Classification destructor
* @return None
*/
~Classification();
/**
* @brief Static image preprocessing
* @param ori_img Original image
* @return None
*/
void pre_process(cv::Mat ori_img);
/**
* @brief Video stream preprocessing (ai2d for ISP)
* @return None
*/
void pre_process();
/**
* @brief kmodel inference
* @return None
*/
void inference();
/**
* @brief kmodel inference result postprocessing
* @param results Postprocessed classification results based on the original image
* @return None
*/
void post_process(vector<cls_res> &results);
private:
/**
* @brief Calculates exp
* @param x Input value
* @return Returns the result of calculating exp
*/
float fast_exp(float x);
/**
* @brief Calculates sigmoid
* @param x Input value
* @return Returns the result of calculating sigmoid
*/
float sigmoid(float x);
std::unique_ptr<ai2d_builder> ai2d_builder_; // ai2d builder
runtime_tensor ai2d_in_tensor_; // ai2d input tensor
runtime_tensor ai2d_out_tensor_; // ai2d output tensor
uintptr_t vaddr_; // ISP virtual address
FrameCHWSize isp_shape_; // ISP corresponding address size
float cls_thresh; // Classification threshold
vector<string> labels; // Class names
int num_class; // Number of classes
float* output; // Reads kmodel output, float pointer type
};
#endif
The above interfaces are implemented in classification.cc:
#include "classification.h"
/*
Static image inference, constructor
*/
Classification::Classification(std::string &kmodel_path, std::string &image_path,std::vector<std::string> labels_,float cls_thresh_,const int debug_mode)
:AIBase(kmodel_path.c_str(),"Classification", debug_mode)
{
cls_thresh=cls_thresh_;
labels=labels_;
num_class = labels.size();
ai2d_out_tensor_ = this->get_input_tensor(0); // Inherited from AIBase interface
}
/*
Video stream inference, constructor
*/
Classification::Classification(std::string &kmodel_path, std::string &image_path,std::vector<std::string> labels_,float cls_thresh_, FrameCHWSize isp_shape, uintptr_t vaddr, uintptr_t paddr,const int debug_mode)
:AIBase(kmodel_path.c_str(),"Classification", debug_mode)
{
cls_thresh=cls_thresh_;
labels=labels_;
num_class = labels.size();
vaddr_ = vaddr;
isp_shape_ = isp_shape;
dims_t in_shape{1, isp_shape.channel, isp_shape.height, isp_shape.width};
ai2d_in_tensor_ = hrt::create(typecode_t::dt_uint8, in_shape, hrt::pool_shared).expect("create ai2d input tensor failed");
ai2d_out_tensor_ = this -> get_input_tensor(0);
Utils::resize(ai2d_builder_, ai2d_in_tensor_, ai2d_out_tensor_);
}
/*
descructor
*/
Classification::~Classification()
{
}
/*
Static image preprocessing function
*/
void Classification::pre_process(cv::Mat ori_img)
{
// Timing
ScopedTiming st(model_name_ + " pre_process image", debug_mode_);
std::vector<uint8_t> chw_vec;
// Convert BGR to RGB, HWC to CHW
Utils::bgr2rgb_and_hwc2chw(ori_img, chw_vec);
//resize
Utils::resize({ori_img.channels(), ori_img.rows, ori_img.cols}, chw_vec, ai2d_out_tensor_);
}
/*
Video stream preprocessing, refer to the AI2D application section for details
*/
void Classification::pre_process()
{
ScopedTiming st(model_name_ + " pre_process video", debug_mode_);
size_t isp_size = isp_shape_.channel * isp_shape_.height * isp_shape_.width;
auto buf = ai2d_in_tensor_.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_write).unwrap().buffer();
memcpy(reinterpret_cast<char *>(buf.data()), (void *)vaddr_, isp_size);
hrt::sync(ai2d_in_tensor_, sync_op_t::sync_write_back, true).expect("sync write_back failed");
ai2d_builder_->invoke(ai2d_in_tensor_, ai2d_out_tensor_).expect("error occurred in ai2d running");
}
/*
Inference functions, run() and get_output(), inherited from AIBase
*/
void Classification::inference()
{
this->run();
this->get_output();
}
/*
Post-processing calculation exp
*/
float Classification::fast_exp(float x)
{
union {
uint32_t i;
float f;
} v{};
v.i = (1 << 23) * (1.4426950409 * x + 126.93490512f);
return v.f;
}
/*
Post-processing calculation sigmoid
*/
float Classification::sigmoid(float x)
{
return 1.0f / (1.0f + fast_exp(-x));
}
/*
post-processing function
*/
void Classification::post_process(vector<cls_res> &results)
{
ScopedTiming st(model_name_ + " post_process", debug_mode_);
// p_outputs_ contains float pointers pointing to the output
output = p_outputs_[0];
cls_res b;
// If multi-class classification
if(num_class > 2){
float sum = 0.0;
for (int i = 0; i < num_class; i++){
sum += exp(output[i]);
}
b.score = cls_thresh;
int max_index;
//softmax processing
for (int i = 0; i < num_class; i++)
{
output[i] = exp(output[i]) / sum;
}
max_index = max_element(output,output+num_class) - output;
if (output[max_index] >= b.score)
{
b.label = labels[max_index];
b.score = output[max_index];
results.push_back(b);
}
}
else// Binary classification
{
float pre = sigmoid(output[0]);
if (pre > cls_thresh)
{
b.label = labels[0];
b.score = pre;
}
else{
b.label = labels[1];
b.score = 1 - pre;
}
results.push_back(b);
}
}
In the preprocessing section of the above code, some utility functions are used, which we have encapsulated in utils.h:
#ifndef UTILS_H
#define UTILS_H
#include <algorithm>
#include <vector>
#include <iostream>
#include <fstream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#include <nncase/functional/ai2d/ai2d_builder.h>
#include <string>
#include <string.h>
#include <cmath>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <unistd.h>
#include <stdint.h>
#include <random>
using namespace nncase;
using namespace nncase::runtime;
using namespace nncase::runtime::k230;
using namespace nncase::F::k230;
using namespace std;
using namespace cv;
using cv::Mat;
using std::cout;
using std::endl;
using std::ifstream;
using std::vector;
#define STAGE_NUM 3
#define STRIDE_NUM 3
#define LABELS_NUM 1
/**
* @brief Structure for classification results
*/
typedef struct cls_res
{
float score; //Classification score
string label; //Classification label result
}cls_res;
/**
* @brief Size of a single image/frame
*/
typedef struct FrameSize
{
size_t width; // image width
size_t height; // image height
} FrameSize;
/**
* @brief Size of a single image/frame in CHW format
*/
typedef struct FrameCHWSize
{
size_t channel; // Channel
size_t height; // Height
size_t width; // Width
} FrameCHWSize;
/**
* @brief AI utility class
* Encapsulates commonly used AI functions, including binary file reading, file saving, image preprocessing, etc.
*/
class Utils
{
public:
/**
* @brief image resize
* @param ori_img Original image
* @param frame_size Size of the image to be resized
* @param padding Pixels to be padded, default is cv::Scalar(104, 117, 123), BGR
* @return Processed image
*/
static cv::Mat resize(const cv::Mat ori_img, const FrameSize &frame_size);
/**
* @brief Convert BGR image from HWC to CHW
* @param ori_img Original image
* @param chw_vec Data converted to CHW
* @return None
*/
static void bgr2rgb_and_hwc2chw(cv::Mat &ori_img, std::vector<uint8_t> &chw_vec);
/*************************for ai2d ori_img process********************/
// resize
/**
* @brief Resize function for CHW data
* @param ori_shape Original CHW data
* @param chw_vec Original data
* @param ai2d_out_tensor AI2D output
* @return None
*/
static void resize(FrameCHWSize ori_shape, std::vector<uint8_t> &chw_vec, runtime_tensor &ai2d_out_tensor);
/**
* @brief resize function
* @param builder AI2D builder for running AI2D
* @param ai2d_in_tensor AI2D input
* @param ai2d_out_tensor AI2D output
* @return None
*/
static void resize(std::unique_ptr<ai2d_builder> &builder, runtime_tensor &ai2d_in_tensor, runtime_tensor &ai2d_out_tensor);
/**
* @brief Draw classification results on the image
* @param frame Original image
* @param results Classification results
* @return None
*/
static void draw_cls_res(cv::Mat& frame, vector<cls_res>& results);
/**
* @brief Draw classification results on the screen's OSD
* @param frame Original image
* @param results Classification results
* @param osd_frame_size OSD width and height
* @param sensor_frame_size Sensor width and height
* @return None
*/
static void draw_cls_res(cv::Mat& frame, vector<cls_res>& results, FrameSize osd_frame_size, FrameSize sensor_frame_size);
};
#endif
If needed, you can add other utility functions. Below is the utils.cc file, which implements the utility class interfaces:
#include <iostream>
#include "utils.h"
using std::ofstream;
using std::vector;
auto cache = cv::Mat::zeros(1, 1, CV_32FC1);
cv::Mat Utils::resize(const cv::Mat img, const FrameSize &frame_size)
{
cv::Mat cropped_img;
cv::resize(img, cropped_img, cv::Size(frame_size.width, frame_size.height), cv::INTER_LINEAR);
return cropped_img;
}
void Utils::bgr2rgb_and_hwc2chw(cv::Mat &ori_img, std::vector<uint8_t> &chw_vec)
{
// for bgr format
std::vector<cv::Mat> bgrChannels(3);
cv::split(ori_img, bgrChannels);
for (auto i = 2; i > -1; i--)
{
std::vector<uint8_t> data = std::vector<uint8_t>(bgrChannels[i].reshape(1, 1));
chw_vec.insert(chw_vec.end(), data.begin(), data.end());
}
}
void Utils::resize(FrameCHWSize ori_shape, std::vector<uint8_t> &chw_vec, runtime_tensor &ai2d_out_tensor)
{
// build ai2d_in_tensor
dims_t in_shape{1, ori_shape.channel, ori_shape.height, ori_shape.width};
runtime_tensor ai2d_in_tensor = host_runtime_tensor::create(typecode_t::dt_uint8, in_shape, hrt::pool_shared).expect("cannot create input tensor");
auto input_buf = ai2d_in_tensor.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_write).unwrap().buffer();
memcpy(reinterpret_cast<char *>(input_buf.data()), chw_vec.data(), chw_vec.size());
hrt::sync(ai2d_in_tensor, sync_op_t::sync_write_back, true).expect("write back input failed");
// run ai2d
// ai2d_datatype_t ai2d_dtype{ai2d_format::NCHW_FMT, ai2d_format::NCHW_FMT, typecode_t::dt_uint8, typecode_t::dt_uint8};
ai2d_datatype_t ai2d_dtype{ai2d_format::NCHW_FMT, ai2d_format::NCHW_FMT, ai2d_in_tensor.datatype(), ai2d_out_tensor.datatype()};
ai2d_crop_param_t crop_param { false, 30, 20, 400, 600 };
ai2d_shift_param_t shift_param{false, 0};
ai2d_pad_param_t pad_param{false, {{0, 0}, {0, 0}, {0, 0}, {0, 0}}, ai2d_pad_mode::constant, {114, 114, 114}};
ai2d_resize_param_t resize_param{true, ai2d_interp_method::tf_bilinear, ai2d_interp_mode::half_pixel};
ai2d_affine_param_t affine_param{false, ai2d_interp_method::cv2_bilinear, 0, 0, 127, 1, {0.5, 0.1, 0.0, 0.1, 0.5, 0.0}};
dims_t out_shape = ai2d_out_tensor.shape();
ai2d_builder builder { in_shape, out_shape, ai2d_dtype, crop_param, shift_param, pad_param, resize_param, affine_param };
builder.build_schedule();
builder.invoke(ai2d_in_tensor,ai2d_out_tensor).expect("error occurred in ai2d running");
}
void Utils::resize(std::unique_ptr<ai2d_builder> &builder, runtime_tensor &ai2d_in_tensor, runtime_tensor &ai2d_out_tensor)
{
// run ai2d
ai2d_datatype_t ai2d_dtype{ai2d_format::NCHW_FMT, ai2d_format::NCHW_FMT, ai2d_in_tensor.datatype(), ai2d_out_tensor.datatype()};
ai2d_crop_param_t crop_param { false, 30, 20, 400, 600 };
ai2d_shift_param_t shift_param{false, 0};
ai2d_pad_param_t pad_param{false, {{0, 0}, {0, 0}, {0, 0}, {0, 0}}, ai2d_pad_mode::constant, {114, 114, 114}};
ai2d_resize_param_t resize_param{true, ai2d_interp_method::tf_bilinear, ai2d_interp_mode::half_pixel};
ai2d_affine_param_t affine_param{false, ai2d_interp_method::cv2_bilinear, 0, 0, 127, 1, {0.5, 0.1, 0.0, 0.1, 0.5, 0.0}};
dims_t in_shape = ai2d_in_tensor.shape();
dims_t out_shape = ai2d_out_tensor.shape();
builder.reset(new ai2d_builder(in_shape, out_shape, ai2d_dtype, crop_param, shift_param, pad_param, resize_param, affine_param));
builder->build_schedule();
builder->invoke(ai2d_in_tensor,ai2d_out_tensor).expect("error occurred in ai2d running");
}
void Utils::draw_cls_res(cv::Mat& frame, vector<cls_res>& results)
{
double fontsize = (frame.cols * frame.rows * 1.0) / (300 * 250);
if (fontsize > 2)
{
fontsize = 2;
}
for(int i = 0; i < results.size(); i++)
{
std::string text = "class: " + results[i].label + ", score: " + std::to_string(round(results[i].score * 100) / 100.0).substr(0, 4);
cv::putText(frame, text, cv::Point(1, 40), cv::FONT_HERSHEY_SIMPLEX, 0.8, cv::Scalar(255, 255, 0), 2);
std::cout << text << std::endl;
}
}
void Utils::draw_cls_res(cv::Mat& frame, vector<cls_res>& results, FrameSize osd_frame_size, FrameSize sensor_frame_size)
{
double fontsize = (frame.cols * frame.rows * 1.0) / (1100 * 1200);
for(int i = 0; i < results.size(); i++)
{
std::string text = "class: " + results[i].label + ", score: " + std::to_string(round(results[i].score * 100) / 100.0).substr(0, 4);
cv::putText(frame, text, cv::Point(1, 40), cv::FONT_HERSHEY_SIMPLEX, 0.8, cv::Scalar(255, 255, 255, 0), 2);
std::cout << text << std::endl;
}
}
For easier debugging, we encapsulated the timing class ScopedTiming in scoped_timing.hpp to measure the time consumed during the lifecycle of an instance of this class。
#include <chrono>
#include <string>
#include <iostream>
/**
* @brief Timing class
* Measure the time consumed during the lifecycle of an instance of this class
*/
class ScopedTiming
{
public:
/**
* @brief ScopedTiming constructor, initializes the timing object name and starts timing
* @param info Timing object name
* @param enable_profile Whether to start timing
* @return None
*/
ScopedTiming(std::string info = "ScopedTiming", int enable_profile = 1)
: m_info(info), enable_profile(enable_profile)
{
if (enable_profile)
{
m_start = std::chrono::steady_clock::now();
}
}
/**
* @brief ScopedTiming destructor, ends timing and prints the elapsed time
* @return None
*/
~ScopedTiming()
{
if (enable_profile)
{
m_stop = std::chrono::steady_clock::now();
double elapsed_ms = std::chrono::duration<double, std::milli>(m_stop - m_start).count();
std::cout << m_info << " took " << elapsed_ms << " ms" << std::endl;
}
}
private:
int enable_profile; // Whether to profile time
std::string m_info; // Timing object name
std::chrono::steady_clock::time_point m_start; // Start time
std::chrono::steady_clock::time_point m_stop; // End time
};
main.cc is the main code for implementing on-board inference. It primarily handles parsing input parameters, printing usage instructions, and implementing inference for two different branches. If the second input parameter is an image path, the image_proc function is called for image inference; if the input is None, the video_proc function is called for video stream inference.
Still image inference code
void image_proc_cls(string &kmodel_path, string &image_path,vector<string> labels,float cls_thresh ,int debug_mode)
{
cv::Mat ori_img = cv::imread(image_path);
int ori_w = ori_img.cols;
int ori_h = ori_img.rows;
//Create task class instance
Classification cls(kmodel_path,image_path,labels,cls_thresh,debug_mode);
//Preprocessing
cls.pre_process(ori_img);
//Inference
cls.inference();
vector<cls_res> results;
//Post-processing
cls.post_process(results);
Utils::draw_cls_res(ori_img,results);
cv::imwrite("result_cls.jpg", ori_img);
}
The above code is the static image inference code section in main.cc. First, it initializes the cv::Mat object ori_img from the image path, then initializes the Classification instance cls. It calls the cls preprocessing function pre_process, the inference function reference, and the post-processing function post_process. Finally, it calls draw_cls_res from utils.h to draw the results on the image and save it as result_cls.jpg. If you need to modify the preprocessing and post-processing parts, you can do so in Classification.cc. If you want to add other utility methods, you can define them in utils and implement them in utils.cc.
The video stream inference code can refer to the example code in Example 2 of the SDK Compilation Chapter. The core AI development code is as follows:
void video_proc_cls(string &kmodel_path, string &image_path,vector<string> labels,float cls_thresh , int debug_mode)
{
// start video capture
vivcap_start();
// create a frame data object
k_video_frame_info vf_info;
// osd
void *pic_vaddr = NULL;
memset(&vf_info, 0, sizeof(vf_info));
vf_info.v_frame.width = osd_width;
vf_info.v_frame.height = osd_height;
vf_info.v_frame.stride[0] = osd_width;
vf_info.v_frame.pixel_format = PIXEL_FORMAT_ARGB_8888;
block = vo_insert_frame(&vf_info, &pic_vaddr);
// alloc memory
size_t paddr = 0;
void *vaddr = nullptr;
size_t size = SENSOR_CHANNEL * SENSOR_HEIGHT * SENSOR_WIDTH;
int ret = kd_mpi_sys_mmz_alloc_cached(&paddr, &vaddr, "allocate", "anonymous", size);
if (ret)
{
std::cerr << "physical_memory_block::allocate failed: ret = " << ret << ", errno = " << strerror(errno) << std::endl;
std::abort();
}
// Initialize the image classification task instance
Classification cls(kmodel_path,image_path,labels,cls_thresh, {SENSOR_CHANNEL, SENSOR_HEIGHT, SENSOR_WIDTH}, reinterpret_cast<uintptr_t>(vaddr), reinterpret_cast<uintptr_t>(paddr), debug_mode);
// Classification results
vector<cls_res> results;
// Perform inference on each frame of the image while not stopped
while (!isp_stop)
{
ScopedTiming st("total time", debug_mode);
{
ScopedTiming st("read capture", debug_mode);
// VICAP_CHN_ID_1 out rgb888p
memset(&dump_info, 0 , sizeof(k_video_frame_info));
// Dump a frame of image to dump_info
ret = kd_mpi_vicap_dump_frame(vicap_dev, VICAP_CHN_ID_1, VICAP_DUMP_YUV, &dump_info, 1000);
if (ret) {
printf("sample_vicap...kd_mpi_vicap_dump_frame failed.\n");
continue;
}
}
{
ScopedTiming st("isp copy", debug_mode);
auto vbvaddr = kd_mpi_sys_mmap_cached(dump_info.v_frame.phys_addr[0], size);
memcpy(vaddr, (void *)vbvaddr, SENSOR_HEIGHT * SENSOR_WIDTH * 3);
kd_mpi_sys_munmap(vbvaddr, size);
}
// Clear results, prepare to save inference results
results.clear();
//Preprocessing
cls.pre_process();
// Inference
cls.inference();
// Post-processing
cls.post_process(results);
// Create OSD frame
cv::Mat osd_frame(osd_height, osd_width, CV_8UC4, cv::Scalar(0, 0, 0, 0));
//Draw results on OSD
{
ScopedTiming st("osd draw", debug_mode);
Utils::draw_cls_res(osd_frame, results, {osd_width, osd_height}, {SENSOR_WIDTH, SENSOR_HEIGHT});
}
// Insert the drawn OSD frame into the output display channel
{
ScopedTiming st("osd copy", debug_mode);
memcpy(pic_vaddr, osd_frame.data, osd_width * osd_height * 4);
//Insert frame into display channel
kd_mpi_vo_chn_insert_frame(osd_id+3, &vf_info); //K_VO_OSD0
printf("kd_mpi_vo_chn_insert_frame success \n");
ret = kd_mpi_vicap_dump_release(vicap_dev, VICAP_CHN_ID_1, &dump_info);
if (ret) {
printf("sample_vicap...kd_mpi_vicap_dump_release failed.\n");
}
}
}
// Termination
vo_osd_release_block();
vivcap_stop();
// free memory
ret = kd_mpi_sys_mmz_free(paddr, vaddr);
if (ret)
{
std::cerr << "free failed: ret = " << ret << ", errno = " << strerror(errno) << std::endl;
std::abort();
}
}
For convenience, we have encapsulated the video stream processing part. You can refer to the example code in K230_training_scripts/end2end_cls_doc at main · kendryte/K230_training_scripts (github.com) in the k230_code directory, specifically the vi_vo.h file and the implementation in main.cc.
k230_code/k230_deploy/CMakeLists.txt
This is the CMakeLists.txt script in the k230_code/k230_deploy directory, which sets the C++ files to be compiled and the name of the generated elf executable file, as follows:
set(src main.cc utils.cc ai_base.cc classification.cc)
set(bin main.elf)
#Add the project's root directory to the header file search path
include_directories(${PROJECT_SOURCE_DIR})
#Add the header file directory of the nncase RISC-V vector library
include_directories(${nncase_sdk_root}/riscv64/rvvlib/include)
#Add the user application API header file directory in the k230 SDK
include_directories(${k230_sdk}/src/big/mpp/userapps/api/)
#Add the header file directory of the mpp (Media Process Platform) in the k230 SDK
include_directories(${k230_sdk}/src/big/mpp/include)
# Add the header file directory related to mpp
include_directories(${k230_sdk}/src/big/mpp/include/comm)
#Add the header file directory of the sample VO (video output) application
include_directories(${k230_sdk}/src/big/mpp/userapps/sample/sample_vo)
#Add the linker search path, pointing to the directory of the nncase RISC-V vector library
link_directories(${nncase_sdk_root}/riscv64/rvvlib/)
#Create an executable file, using the previously set source file list as input
add_executable(${bin} ${src})
#Set the libraries that the executable file needs to link to. The list includes various libraries, including nncase-related libraries, k230 SDK libraries, and some other libraries
target_link_libraries(${bin} ...)
#Link some OpenCV-related libraries and some other third-party libraries to the executable file
target_link_libraries(${bin} opencv_imgproc opencv_imgcodecs opencv_core zlib libjpeg-turbo libopenjp2 libpng libtiff libwebp csi_cv)
# Install the generated executable file to the specified target path (bin directory)
install(TARGETS ${bin} DESTINATION bin)
k230_code/CMakeLists.txt
cmake_minimum_required(VERSION 3.2)
project(nncase_sdk C CXX)
# Set the root directory of nncase, located in src/big/nncase. You can also set it as an absolute path
set(nncase_sdk_root "${PROJECT_SOURCE_DIR}/../../nncase/")
# Set the root directory of k230_sdk, currently obtained from the third-level parent directory of nncase. You can also set it as an absolute path
set(k230_sdk ${nncase_sdk_root}/../../../)
#Set the linker script path, the linker script is placed in k230_code/cmake
set(CMAKE_EXE_LINKER_FLAGS "-T ${PROJECT_SOURCE_DIR}/cmake/link.lds --static")
# set opencv
set(k230_opencv ${k230_sdk}/src/big/utils/lib/opencv)
include_directories(${k230_opencv}/include/opencv4/)
link_directories(${k230_opencv}/lib ${k230_opencv}/lib/opencv4/3rdparty)
# set mmz
link_directories(${k230_sdk}/src/big/mpp/userapps/lib)
# set nncase
include_directories(${nncase_sdk_root}/riscv64)
include_directories(${nncase_sdk_root}/riscv64/nncase/include)
include_directories(${nncase_sdk_root}/riscv64/nncase/include/nncase/runtime)
link_directories(${nncase_sdk_root}/riscv64/nncase/lib/)
# Add subprojects to be compiled
add_subdirectory(k230_deploy)
k230_code/build_app.sh
#!/bin/bash
set -x
# set cross build toolchain
# Add the path of the cross-compilation toolchain to the system's PATH environment variable for subsequent commands. This toolchain is the big-core compilation toolchain.
export PATH=$PATH:/opt/toolchain/riscv64-linux-musleabi_for_x86_64-pc-linux-gnu/bin/
clear
rm -rf out
mkdir out
pushd out
cmake -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=`pwd` \
-DCMAKE_TOOLCHAIN_FILE=cmake/Riscv64.cmake \
..
make -j && make install
popd
# The generated main.elf can be found in the k230_bin folder under the k230_code directory
k230_bin=`pwd`/k230_bin
rm -rf ${k230_bin}
mkdir -p ${k230_bin}
if [ -f out/bin/main.elf ]; then
cp out/bin/main.elf ${k230_bin}
fi
10.1.5.3 Code Compilation#
Copy the k230_code folder from the project to the src/big/nncase directory under the k230_sdk directory, and execute the compilation script to compile the C++ code into the main.elf executable file.
# If you are burning Linux+RT-Smart dual system image, execute in the k230_SDK root directory
make CONF=k230_canmv_defconfig prepare_memory
# If you are burning a pure RT-Smart single system image, execute in the k230_SDK root directory
make CONF=k230_canmv_only_rtt_defconfig prepare_memory
# Return to the current project directory and grant permissions
chmod +x build_app.sh
./build_app.sh
10.1.5.4 Preparing the ELF File#
The files needed for the subsequent deployment steps include:
k230_code/k230_bin/main.elf;
10.1.6 Network Configuration and File Copying#
There are three ways to copy the files to be used onto the development board.
10.1.6.1 Offline File Copying#
Note: This method is applicable to Linux+RT-Smart dual-system image and pure RT-Smart single-system image;
By inserting and removing the SD card, copy the required files to the appropriate location. The root directory of the SD card maps to the /sharefs directory of the big and small cores.
10.1.6.2 TFTP File Transfer#
Note: This method is only applicable to Linux+RT-Smart dual-system images; for pure RT-Smart single system, please choose the offline copy method;
Network Configuration on Windows PC
Control Panel -> Network and Sharing Center -> Change Adapter Settings -> Ethernet Adapter -> Right-click Properties -> Select (TCP/IPv4) -> Properties
Configure IP address, subnet mask, gateway, and DNS server address:
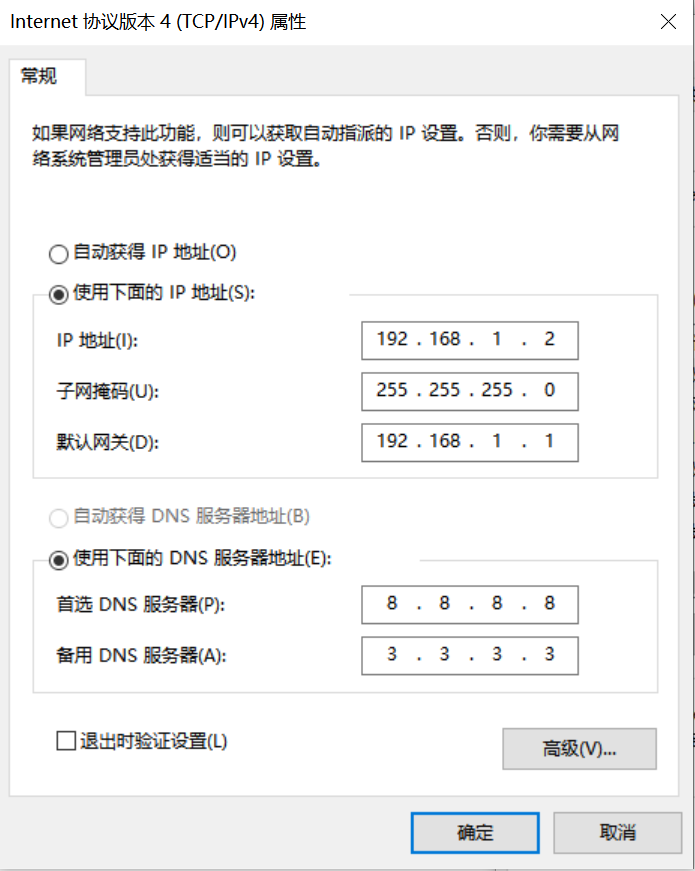
Development Board Network Configuration
Enter the small core command line and execute:
# Check if eth0 exists
ifconfig
# Configure the development board IP to be in the same subnet as the PC
ifconfig eth0 192.168.1.22
# Check IP configuration
ifconfig
Tool: tftpd64
Install the tftp communication tool, download link: https://bitbucket.org/phjounin/tftpd64/downloads/
Start tftpd64 and configure the directory for storing files to be transferred and the service network card.
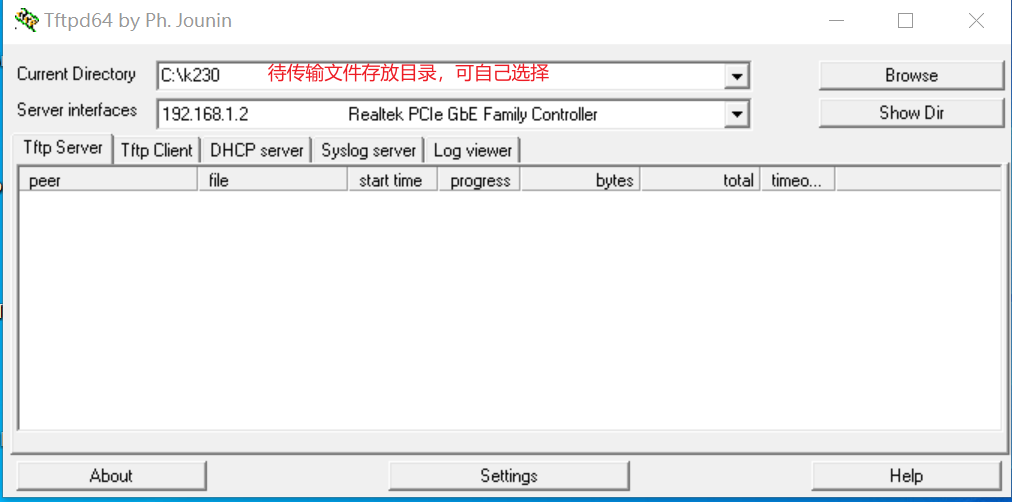
Explanation of sharefs
# Enter the root directory of the small core
cd /
# View directories
ls
# The sharefs directory is a shared directory for both the small and large cores, so files copied to the sharefs directory from the small core are also visible to the large core.
File Transfer
# The following code is executed in the small core serial port
# Transfer files from the directory configured in tftpd64 on the PC to the current directory on the development board
tftp -g -r your_file 192.168.1.2
# Transfer files from the current directory on the development board to the directory configured in tftpd64 on the PC
tftp -p -r board_file 192.168.1.2
10.1.6.2 SCP File Transfer#
Note: This method is only applicable to Linux+RT-Smart dual-system images; for pure RT-Smart single system, please choose the offline copy method;
In a Linux system, with the PC normally connected to the network, the development board can connect to other network ports under the same gateway as the PC via an Ethernet cable, and file transfer can be achieved using the scp command.
Power on the development board and enter the COM interface for both the small and large cores. Execute the scp transfer command in the small core:
# Copy files from the PC to the development board
scp username@hostname_or_IP:source_directory destination_directory_on_board
# Copy folders
scp -r username@hostname_or_IP:source_directory destination_directory_on_board
# Copy files from the development board to the PC
scp source_directory_on_board username@hostname_or_IP:destination_directory_on_PC
# Copy folders
scp -r source_directory_on_board username@hostname_or_IP:destination_directory_on_PC
10.1.7 K230-side Deployment#
10.1.7.1 Board-side Deployment Process#
According to the file copying process provided in the previous section, copy the files prepared for the model training and testing part and the elf file prepared for the C++ code compilation part to the development board. The Linux+RT-Smart dual system is in /sharefs, and the pure RT-Smart is in /sdcard. Create a folder test_cls:
test_cls
├──best.kmodel
├──labels.txt
├──main.elf
├──test.jpg
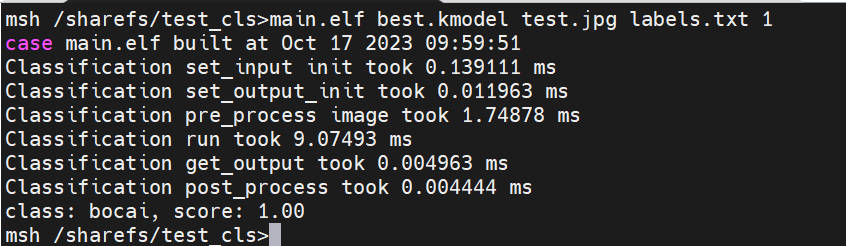
To perform static image inference, execute the following code (Note: The code needs to be executed in the large core):
# Linux+RT-Smart
cd /sharefs/test_cls
# Only RT-Smart
cd /sdcard/test_cls
# "Model inference parameter explanation:"
# "<kmodel_path> <image_path> <labels_txt> <debug_mode>"
# "Options:"
# " kmodel_path Path to the kmodel\n"
# " image_path Path to the image for inference/camera (None)\n"
# " labels_txt Path to the class label file\n"
# " debug_mode Whether debugging is needed, 0, 1, 2 represent no debugging, simple debugging, and detailed debugging respectively\n"
main.elf best.kmodel test.jpg labels.txt 2
For camera video stream inference, execute the following code:
main.elf best.kmodel None labels.txt 2
10.1.7.2 Board Deployment Results#
Static image inference illustration:
Video stream inference illustration:

10.2 Using KTS for Object Detection Tasks#
10.2.1 Environment Setup#
Linux system;
Install GPU drivers;
Install Anaconda to create a model training environment;
Install Docker to create an SDK image compilation environment;
Install the dotnet SDK;
10.2.2 Data Preparation#
Organize the custom dataset for the object detection task in the following format. The root directory includes subdirectories named after class names, and each subdirectory contains all image samples of its class.
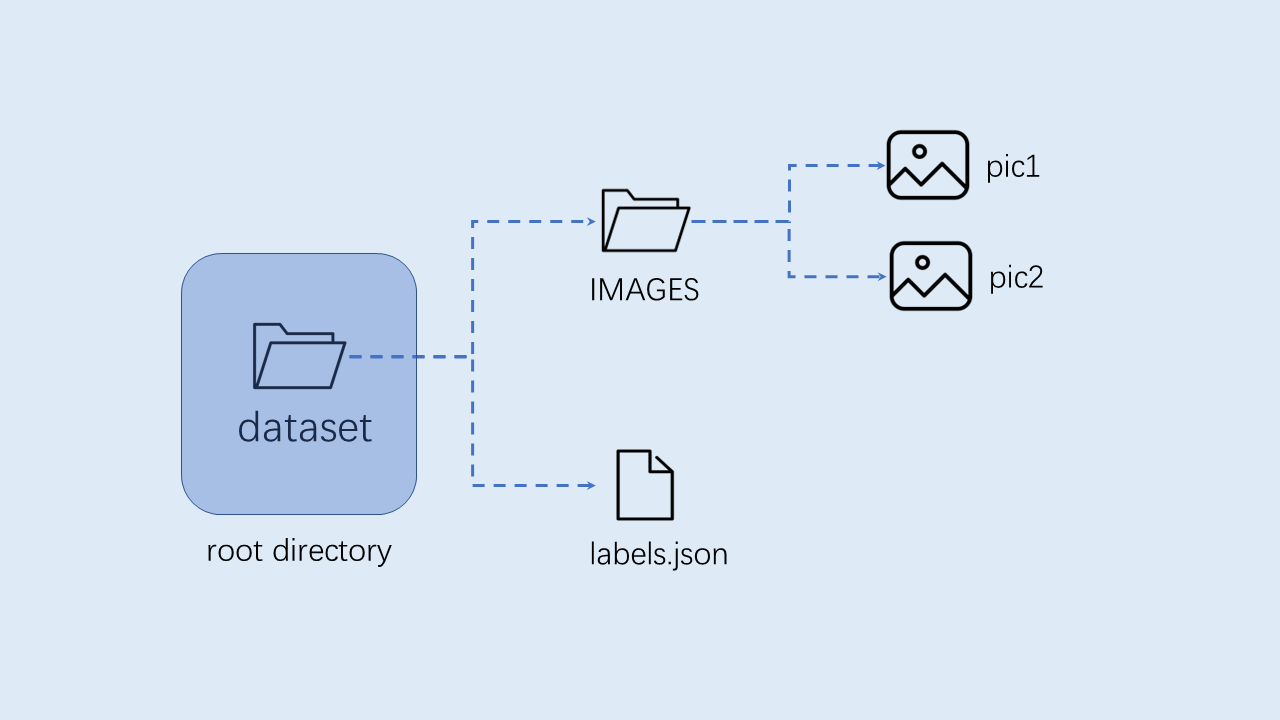
10.2.3 Model Training and Testing#
This section is implemented in the training environment.
10.2.3.1 Create a Virtual Environment#
Open the command terminal:
conda create -n myenv python=3.9
conda activate myenv
10.2.3.2 Install Python Dependencies#
Install the Python libraries used for training according to the requirements.txt file in the project, and wait for the installation to complete:
pip install -r requirements.txt
The requirements.txt file will install the model conversion packages nncase and nncase-kpu. nncase is a neural network compiler designed for AI accelerators.
When compiling images and using nncase to convert kmodels, pay attention to the version compatibility. For the corresponding relationship between k230_sdk versions and nncase versions, refer to the following link:
K230 SDK nncase Version Compatibility — K230 Documentation (canaan-creative.com)
You can replace the nncase and nncase-kpu versions according to the corresponding versions, for example, to change the nncase version to 2.7.0:
pip install nncase==2.7.0
pip install nncase-kpu==2.7.0
10.2.3.3 Configure Training Parameters#
The configuration file yaml/config.yaml in the provided training script is set as follows:
dataset:
root_folder: ../data/fruit # Path to the object detection dataset
origion_json: labels.json # Annotation json file for the object detection dataset
split: true # Whether to re-split, must be true for the first run
val_ratio: 0.1 # Validation set ratio
test_ratio: 0.1 # Test set ratio
train_val_test:
json_dir: ../gen # Path for the generated json files for training, validation, and test sets, label names file, and calibration set file
model_save_dir: ../checkpoints # Path to save the model
gpu_index: 0 # Index of the GPU to be used, if the GPU is unavailable, the CPU will be used
img_size: 640 # Resolution
learningrate: 0.001 # Learning rate
mean: [ 0.485, 0.456, 0.406 ] # Image normalization mean
std: [ 0.229, 0.224, 0.225 ] # Image normalization standard deviation
epochs: 300 # Number of training iterations
nms_option: false # Whether to perform NMS within classes or between classes, false represents within classes
pre_train_dir: pre_pth # Path to store pre-trained models
train_batch_size: 32 # Training batch size
val_batch_size: 8 # Validation batch size
test_batch_size: 8 # Test batch size
inference:
mode: image # Inference mode, divided into image and video; in image mode, you can infer a single image or all images in a directory, in video mode, you can infer using the camera
inference_model: best # Divided into best and last, calling best.pth and last.pth under checkpoints respectively for inference
image_path: ../data/fruit/test.jpg # If this path is an image path, single image inference is performed; if it is a directory, inference is performed on all images in the directory
deploy_json: deploy.json # Parameter file to be read by kmodel later
confidence_threshold: 0.55 # Detection box threshold
nms_threshold: 0.2 # Non-maximum suppression threshold
deploy:
onnx_img_size: [640,640] # Input resolution for converting to onnx [w, h], must be a multiple of 32
chip: k230 # Chip type, divided into "k230" and "cpu"
ptq_option: 0 # Quantization type, 0 is uint8, 1, 2, 3, 4 are different forms of uint16
10.2.3.4 Model Training#
Enter the scripts directory of the project and execute the training code:
python3 main.py
If the training is successful, you can find the trained last.pth, best.pth, best.onnx, and best.kmodel in the model_save_dir directory specified in the configuration file.
10.2.3.5 Model Testing#
Set the inference part of the configuration file, set the test configuration, and execute the test code:
python3 inference.py
10.2.3.6 Prepare Files#
The files needed for the subsequent deployment steps include:
checkpoints/best.kmodel;
gen/deploy.json;
Test image test.jpg;
10.2.4 K230_SDK Image Compilation and Burning#
When compiling images and using nncase to convert kmodels, pay attention to the version compatibility. For the corresponding relationship between k230_sdk versions and nncase versions, refer to the following link:
K230 SDK nncase Version Compatibility — K230 Documentation (canaan-creative.com)
If you choose to use the images provided in the Images section of the Canaan Developer Community (canaan-creative.com), please pay attention to the version compatibility when downloading and burning.
10.2.4.1 Docker Environment Setup#
# Download the docker compilation image
docker pull ghcr.io/kendryte/k230_sdk
# You can use the following command to confirm whether the docker image was successfully pulled
docker images | grep ghcr.io/kendryte/k230_sdk
# Download the SDK source code
git clone https://github.com/kendryte/k230_sdk.git
cd k230_sdk
# Download the toolchain (Linux and RT-Smart toolchain, buildroot package, AI package, etc.)
make prepare_sourcecode
# Create a docker container, $(pwd):$(pwd) maps the current directory to the same directory inside the docker container, and maps the toolchain directory on the system to the /opt/toolchain directory inside the docker container
docker run -u root -it -v $(pwd):$(pwd) -v $(pwd)/toolchain:/opt/toolchain -w $(pwd) ghcr.io/kendryte/k230_sdk /bin/bash
10.2.4.2 Image Compilation#
Please execute the following commands in the k230_sdk root directory according to different system requirements:
# (1)If you choose to compile the Linux+RT-Smart dual system image yourself, execute the following command
make CONF=k230_canmv_defconfig
# (2)If you choose to use the Linux+RT-Smart dual system image downloaded from the developer community, be sure to execute the following command in the k230_sdk root directory to specify the development board type
make mpp
make CONF=k230_canmv_defconfig prepare_memory
# (3)If you choose to compile a pure RT-Smart system image yourself, execute the following command. The developer community has not yet opened the pure RT-Smart image download
make CONF=k230_canmv_only_rtt_defconfig
Please wait patiently for the image to compile successfully.
For Linux+RT-Smart dual system compilation, download the compiled image from k230_sdk root directory/output/k230_canmv_defconfig/images and flash it to the SD card. Refer to Image Flashing for flashing steps:
k230_canmv_defconfig/images ├── big-core ├── little-core ├── sysimage-sdcard.img # SD card boot image └── sysimage-sdcard.img.gz # Compressed SD card boot image
For RT-Smart single system compilation, download the compiled image from k230_sdk root directory/output/k230_canmv_only_rtt_defconfig/images and flash it to the SD card. Refer to Image Flashing for flashing steps:
k230_canmv_defconfig/images ├── big-core ├── sysimage-sdcard.img # SD card boot image └── sysimage-sdcard.img.gz # Compressed SD card boot image
10.2.4.3 Image Burning#
CANMV K230 supports the SDCard boot method. For convenience in development, it is recommended to prepare a TF card (Micro SD card).
Linux:
Before inserting the SD card into the host machine, enter:
ls -l /dev/sd\*
to view the current storage devices.
After inserting the TF card into the host machine, enter again:
ls -l /dev/sd\*
to view the storage devices at this time. The newly added device is the TF card device node.
Assuming /dev/sdc is the TF card device node, execute the following command to burn the TF card:
sudo dd if=sysimage-sdcard.img of=/dev/sdc bs=1M oflag=sync
Windows:
On Windows, you can use the rufus tool to burn the TF card. Download the rufus tool here.
Insert the SD card into the PC, then start the rufus tool, click the “Select” button in the tool interface, and choose the firmware to be burned.
Click the “Start” button to start burning. The burning process has a progress bar display, and after burning is complete, it will prompt “Ready”.
10.2.4.4 Power on the Development Board#
Install MobaXterm for serial communication. Download MobaXterm at: https://mobaxterm.mobatek.net.
Insert the burned SD card into the board slot, connect HDMI output to the monitor, connect the Ethernet port to the Ethernet, and connect the POWER port to the serial port and power supply. After powering on the system, there will be two serial devices by default, which can be used to access the small-core Linux and the large-core RTSmart respectively.
The default username for small-core Linux is root, and the password is empty. The large-core RTSmart system will automatically start an application at boot, which can be exited to the command prompt terminal by pressing the q key.
10.2.5 C++ Code Compilation#
10.2.5.1 Code Structure#
After completing the preparation of the development board, we can use C++ to write our own code. Below is an analysis of the example code for the object detection task. This tutorial provides related example code for the object detection task and analyzes it. Refer to the example code at: kendryte/K230_training_scripts
k230_code
├──cmake
├──link.lds # Link script
├──Riscv64.cmake
├──k230_deploy
├──ai_base.cc # Model deployment base class implementation
├──ai_base.h # Model deployment base class, encapsulates nncase loading, input setting, model inference, and output retrieval operations. Subsequent specific task development only needs to focus on model preprocessing and postprocessing.
├──anchorbase_det.cc # Object detection code class implementation
├──anchorbase_det.h # Object detection class definition, inherits AIBase, used to load kmodel to implement object detection tasks, encapsulates model inference preprocessing and postprocessing
├──main.cc # Main function, parameter parsing, initialization of the AnchorBaseDet class instance, and implementation of on-board functionality
├──scoped_timing.hpp # Timing tool
├──utils.cc # Utility class implementation
├──utils.h # Utility class, encapsulates common functions for image preprocessing and object detection tasks, including reading binary files, saving images, image processing, result drawing, etc. Users can enrich this file according to their needs.
├──vi_vo.h # Video input-output header file
├──json.h # JSON file parsing header file
├──json.cpp # JSON file parsing interface implementation
├──CMakeLists.txt # CMake script for building an executable file using C/C++ source files and linking to various libraries
├──build_app.sh # Compilation script, uses the cross-compilation toolchain to compile the k230_deploy project
├──CMakeLists.txt # CMake script for building the nncase_sdk project
10.2.5.2 Core Code#
Once you have the kmodel model, the specific AI on-board code includes steps such as sensor & display initialization, kmodel loading, model input-output setting, image acquisition, input data loading, input data preprocessing, model inference, model output retrieval, output postprocessing, OSD display, etc. As shown in the diagram:
The yellow boxed part in the figure provides interfaces in vi_vo.h. Below, we introduce how to develop AI applications focusing on the red boxed part.
In the above process, kmodel loading, model input setting, model inference, and model output retrieval are common steps for all tasks. We have encapsulated these steps, and ai_base.h and ai_base.cc can be directly copied for use.
ai_base.h defines the AIBase base class and the interfaces for common operations:
#ifndef AI_BASE_H
#define AI_BASE_H
#include <vector>
#include <string>
#include <fstream>
#include <nncase/runtime/interpreter.h>
#include "scoped_timing.hpp"
using std::string;
using std::vector;
using namespace nncase::runtime;
/**
* @brief AI base class encapsulating nncase-related operations
* Mainly encapsulates nncase loading, input setting, running, and output retrieval operations. Subsequent demo development only needs to focus on model preprocessing and postprocessing.
*/
class AIBase
{
public:
/**
* @brief AI base class constructor, loads kmodel and initializes kmodel input and output
* @param kmodel_file Path to the kmodel file
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
AIBase(const char *kmodel_file, const string model_name, const int debug_mode = 1);
/**
* @brief AI base class destructor
* @return None
*/
~AIBase();
/**
* @brief Sets kmodel input
* @param buf Pointer to input data
* @param size Size of input data
* @return None
*/
void set_input(const unsigned char *buf, size_t size);
/**
* @brief Gets kmodel input tensor by index
* @param idx Index of input data
* @return None
*/
runtime_tensor get_input_tensor(size_t idx);
/**
* @brief Sets model input tensor by index
* @param idx Index of input data
* @param tensor Input tensor
*/
void set_input_tensor(size_t idx, runtime_tensor &tensor);
/**
* @brief Initializes kmodel output
* @return None
*/
void set_output();
/**
* @brief Inferences kmodel
* @return None
*/
void run();
/**
* @brief Gets kmodel output, results are stored in the corresponding class attributes
* @return None
*/
void get_output();
protected:
string model_name_; // Model name
int debug_mode_; // Debug mode, 0 (no print), 1 (print time), 2 (print all)
vector<float *> p_outputs_; // List of pointers corresponding to kmodel output
vector<vector<int>> input_shapes_; //{{N,C,H,W},{N,C,H,W}...}
vector<vector<int>> output_shapes_; //{{N,C,H,W},{N,C,H,W}...}} or {{N,C},{N,C}...}} etc.
vector<int> each_input_size_by_byte_; //{0,layer1_length,layer1_length+layer2_length,...}
vector<int> each_output_size_by_byte_; //{0,layer1_length,layer1_length+layer2_length,...}
private:
/**
* @brief Initializes kmodel input for the first time and gets input shape
* @return None
*/
void set_input_init();
/**
* @brief Initializes kmodel output for the first time and gets output shape
* @return None
*/
void set_output_init();
vector<unsigned char> kmodel_vec_; // Stores the entire kmodel data by reading the kmodel file, used for loading kmodel by the kmodel interpreter
interpreter kmodel_interp_; // kmodel interpreter, constructed from the kmodel file, responsible for model loading, input-output setting, and inference
};
#endif
ai_base.cc is the specific implementation of all interfaces defined in ai_base.h.
/*
Specific implementation of AIBase class interfaces defined in ai_base.h
*/
#include "ai_base.h"
#include <iostream>
#include <cassert>
#include "utils.h"
using std::cout;
using std::endl;
using namespace nncase;
using namespace nncase::runtime::detail;
/*AIBase constructor*/
AIBase::AIBase(const char *kmodel_file, const string model_name, const int debug_mode) : debug_mode_(debug_mode), model_name_(model_name)
{
if (debug_mode > 1)
cout << "kmodel_file:" << kmodel_file << endl;
std::ifstream ifs(kmodel_file, std::ios::binary); // Read in kmodel
kmodel_interp_.load_model(ifs).expect("Invalid kmodel"); // kmodel interpreter loads kmodel
set_input_init();
set_output_init();
}
/*Destructor*/
AIBase::~AIBase()
{
}
/*
Initializes kmodel input for the first time
*/
void AIBase::set_input_init()
{
ScopedTiming st(model_name_ + " set_input init", debug_mode_); // Timing
int input_total_size = 0;
each_input_size_by_byte_.push_back(0); // First add 0, for later use
for (int i = 0; i < kmodel_interp_.inputs_size(); ++i)
{
auto desc = kmodel_interp_.input_desc(i); // Input description for index i
auto shape = kmodel_interp_.input_shape(i); // Input shape for index i
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create input tensor"); // Create input tensor
kmodel_interp_.input_tensor(i, tensor).expect("cannot set input tensor"); // Bind tensor to model input
vector<int> in_shape = {shape[0], shape[1], shape[2], shape[3]};
input_shapes_.push_back(in_shape); // Store input shape
int dsize = shape[0] * shape[1] * shape[2] * shape[3]; // Total input bytes
if (debug_mode_ > 1)
cout << "input shape:" << shape[0] << " " << shape[1] << " " << shape[2] << " " << shape[3] << endl;
if (desc.datatype == 0x06) // Input data is of type uint8
{
input_total_size += dsize;
each_input_size_by_byte_.push_back(input_total_size);
}
else if (desc.datatype == 0x0B) // Input data is of type float32
{
input_total_size += (dsize * 4);
each_input_size_by_byte_.push_back(input_total_size);
}
else
assert(("kmodel input data type supports only uint8, float32", 0));
}
each_input_size_by_byte_.push_back(input_total_size); // The last one saves the total size
}
/*
Sets model input data, loads specific input data for the model
*/
void AIBase::set_input(const unsigned char *buf, size_t size)
{
// Check if the input data size matches the model's required size
if (*each_input_size_by_byte_.rbegin() != size)
cout << "set_input: the actual input size{" + std::to_string(size) + "} is different from the model's required input size{" + std::to_string(*each_input_size_by_byte_.rbegin()) + "}" << endl;
assert((*each_input_size_by_byte_.rbegin() == size));
// Timing
ScopedTiming st(model_name_ + " set_input", debug_mode_);
// Loop through model inputs
for (size_t i = 0; i < kmodel_interp_.inputs_size(); ++i)
{
// Get model input description and shape
auto desc = kmodel_interp_.input_desc(i);
auto shape = kmodel_interp_.input_shape(i);
// Create tensor
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create input tensor");
// Map input tensor to writable area
auto mapped_buf = std::move(hrt::map(tensor, map_access_::map_write).unwrap()); // mapped_buf actually has cached data
// Copy data to tensor buffer
memcpy(reinterpret_cast<void *>(mapped_buf.buffer().data()), buf, each_input_size_by_byte_[i + 1] - each_input_size_by_byte_[i]);
// Unmap
auto ret = mapped_buf.unmap();
ret = hrt::sync(tensor, sync_op_t::sync_write_back, true);
if (!ret.is_ok())
{
std::cerr << "hrt::sync failed" << std::endl;
std::abort();
}
// Bind tensor to model input
kmodel_interp_.input_tensor(i, tensor).expect("cannot set input tensor");
}
}
/*
Gets model input tensor by index
*/
runtime_tensor AIBase::get_input_tensor(size_t idx)
{
return kmodel_interp_.input_tensor(idx).expect("cannot get input tensor");
}
/*
Sets model input tensor by index
*/
void AIBase::set_input_tensor(size_t idx, runtime_tensor &tensor)
{
ScopedTiming st(model_name_ + " set_input_tensor", debug_mode_);
kmodel_interp_.input_tensor(idx, tensor).expect("cannot set input tensor");
}
/*
Initializes kmodel output for the first time
*/
void AIBase::set_output_init()
{
// Timing
ScopedTiming st(model_name_ + " set_output_init", debug_mode_);
each_output_size_by_byte_.clear();
int output_total_size = 0;
each_output_size_by_byte_.push_back(0);
// Loop through model outputs
for (size_t i = 0; i < kmodel_interp_.outputs_size(); i++)
{
// Get output description and shape
auto desc = kmodel_interp_.output_desc(i);
auto shape = kmodel_interp_.output_shape(i);
vector<int> out_shape;
int dsize = 1;
for (int j = 0; j < shape.size(); ++j)
{
out_shape.push_back(shape[j]);
dsize *= shape[j];
if (debug_mode_ > 1)
cout << shape[j] << ",";
}
if (debug_mode_ > 1)
cout << endl;
output_shapes_.push_back(out_shape);
// Get total data size
if (desc.datatype == 0x0B)
{
output_total_size += (dsize * 4);
each_output_size_by_byte_.push_back(output_total_size);
}
else
assert(("kmodel output data type supports only float32", 0));
// Create tensor
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create output tensor");
// Bind tensor to model output
kmodel_interp_.output_tensor(i, tensor).expect("cannot set output tensor");
}
}
/*
Sets kmodel output
*/
void AIBase::set_output()
{
ScopedTiming st(model_name_ + " set_output", debug_mode_);
// Loop through and bind output tensors to model outputs
for (size_t i = 0; i < kmodel_interp_.outputs_size(); i++)
{
auto desc = kmodel_interp_.output_desc(i);
auto shape = kmodel_interp_.output_shape(i);
auto tensor = host_runtime_tensor::create(desc.datatype, shape, hrt::pool_shared).expect("cannot create output tensor");
kmodel_interp_.output_tensor(i, tensor).expect("cannot set output tensor");
}
}
/*
Calls kmodel_interp_.run() to perform model inference
*/
void AIBase::run()
{
ScopedTiming st(model_name_ + " run", debug_mode_);
kmodel_interp_.run().expect("error occurred in running model");
}
/*
Gets model output (as float pointers, retrieved according to specific postprocessing requirements), preparing for subsequent postprocessing
*/
void AIBase::get_output()
{
ScopedTiming st(model_name_ + " get_output", debug_mode_);
// p_outputs_ stores pointers to model outputs, there can be multiple outputs
p_outputs_.clear();
for (int i = 0; i < kmodel_interp_.outputs_size(); i++)
{
// Get output tensor
auto out = kmodel_interp_.output_tensor(i).expect("cannot get output tensor");
// Map output tensor to host memory
auto buf = out.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_read).unwrap().buffer();
// Convert mapped data to float pointers
float *p_out = reinterpret_cast<float *>(buf.data());
p_outputs_.push_back(p_out);
}
}
Preprocessing and postprocessing vary for different task scenarios, such as using softmax to calculate class probabilities for classification and performing NMS for object detection. Therefore, you can define your task scenario class to inherit from the AIBase class, encapsulating the preprocessing and postprocessing code for that task.
anchorbase_det.h defines the interfaces for model preprocessing and postprocessing related to object detection tasks, and these interfaces are implemented in anchorbase_det.cc.
#ifndef _ANCHORBASE_DET_H
#define _ANCHORBASE_DET_H
#include "utils.h"
#include "ai_base.h"
#define STRIDE_NUM 3
/**
* @brief Multi-object detection
* Mainly encapsulates the process of preprocessing, running, and postprocessing to get results for each frame of the image
*/
class AnchorBaseDet : public AIBase
{
public:
/**
* @brief AnchorBaseDet constructor, loads kmodel and initializes kmodel input, output, and multi-object detection threshold
* @param args Parameters needed to construct the object, config.json file (including detection threshold, etc.)
* @param kmodel_file Path to the kmodel
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
AnchorBaseDet(config_args args, const char *kmodel_file, const int debug_mode = 1);
/**
* @brief AnchorBaseDet constructor, loads kmodel and initializes kmodel input, output, and multi-object detection threshold
* @param args Parameters needed to construct the object, config.json file (including detection threshold, kmodel path, etc.)
* @param kmodel_file Path to the kmodel
* @param isp_shape ISP input size (chw)
* @param vaddr ISP corresponding virtual address
* @param paddr ISP corresponding physical address
* @param debug_mode 0 (no debugging), 1 (show time only), 2 (show all print information)
* @return None
*/
AnchorBaseDet(config_args args, const char *kmodel_file, FrameCHWSize isp_shape, uintptr_t vaddr, uintptr_t paddr, const int debug_mode);
/**
* @brief AnchorBaseDet destructor
* @return None
*/
~AnchorBaseDet();
/**
* @brief Image preprocessing
* @param ori_img Original image
* @return None
*/
void pre_process(cv::Mat ori_img);
/**
* @brief Video stream preprocessing (ai2d for ISP)
* @return None
*/
void pre_process();
/**
* @brief kmodel inference
* @return None
*/
void inference();
/**
* @brief kmodel inference result postprocessing
* @param frame_size Original image/frame width and height, used to place the results in the original image size
* @param results Postprocessed detection results based on the original image
* @return None
*/
void post_process(FrameSize frame_size, vector<ob_det_res> &results);
private:
/**
* @brief Preliminary processing of detection results
* @param data Pointer to the head of a layer of model output
* @param frame_size Original image/frame width and height, used to place the results in the original image size
* @param k Index of the k-th layer of the model
* @return Processed detection box collection
*/
vector<ob_det_res> decode_infer(float* data, FrameSize frame_size, int k);
/**
* @brief Preliminary processing of detection results
* @param data Pointer to the head of a layer of model output
* @param frame_size Original image/frame width and height, used to place the results in the original image size
* @param k Index of the k-th layer of the model
* @return Processed detection box collection
*/
vector<vector<ob_det_res>> decode_infer_class(float* data, FrameSize frame_size, int k);
/**
* @brief Performs non-maximum suppression on detection results
* @param input_boxes Collection of detection boxes
* @return None
*/
void nms(vector<ob_det_res>& input_boxes);
std::unique_ptr<ai2d_builder> ai2d_builder_; // ai2d builder
runtime_tensor ai2d_in_tensor_; // ai2d input tensor
runtime_tensor ai2d_out_tensor_; // ai2d output tensor
uintptr_t vaddr_; // ISP virtual address
FrameCHWSize isp_shape_; // ISP corresponding address size
float ob_det_thresh; // Detection box score threshold
float ob_nms_thresh; // NMS threshold
vector<string> labels; // Class names
int num_class; // Number of classes
int strides[STRIDE_NUM]; // Resolution reduction factor for each layer of detection results
float anchors[3][3][2]; // Preset anchors for detection
bool nms_option;
int input_height; // Model input height
int input_width; // Model input width
float *output_0; // Reads kmodel output
float *output_1; // Reads kmodel output
float *output_2; // Reads kmodel output
};
#endif
anchorbase_det.cc is the specific implementation of the object detection related preprocessing and postprocessing interfaces in anchorbase_det.h.
#include "anchorbase_det.h"
/*
* Static image inference constructor, inherits AI
*/
AnchorBaseDet::AnchorBaseDet(config_args args, const char *kmodel_file, const int debug_mode)
:ob_det_thresh(args.obj_thresh),ob_nms_thresh(args.nms_thresh),labels(args.labels), AIBase(kmodel_file,"AnchorBaseDet", debug_mode)
{
nms_option = args.nms_option;
num_class = labels.size();
memcpy(this->strides, args.strides, sizeof(args.strides));
memcpy(this->anchors, args.anchors, sizeof(args.anchors));
input_width = input_shapes_[0][3];
input_height = input_shapes_[0][2];
ai2d_out_tensor_ = this -> get_input_tensor(0);
}
/*
*Constructor for video stream inference, inheriting from AIBase, parameter initialization
*/
AnchorBaseDet::AnchorBaseDet(config_args args, const char *kmodel_file, FrameCHWSize isp_shape, uintptr_t vaddr, uintptr_t paddr,const int debug_mode)
:ob_det_thresh(args.obj_thresh),ob_nms_thresh(args.nms_thresh),labels(args.labels), AIBase(kmodel_file,"AnchorBaseDet", debug_mode)
{
nms_option = args.nms_option;
num_class = labels.size();
memcpy(this->strides, args.strides, sizeof(args.strides));
memcpy(this->anchors, args.anchors, sizeof(args.anchors));
input_width = input_shapes_[0][3];
input_height = input_shapes_[0][2];
vaddr_ = vaddr;
isp_shape_ = isp_shape;
dims_t in_shape{1, isp_shape.channel, isp_shape.height, isp_shape.width};
ai2d_in_tensor_ = hrt::create(typecode_t::dt_uint8, in_shape, hrt::pool_shared).expect("create ai2d input tensor failed");
ai2d_out_tensor_ = this -> get_input_tensor(0);
Utils::padding_resize(isp_shape, {input_shapes_[0][3], input_shapes_[0][2]}, ai2d_builder_, ai2d_in_tensor_, ai2d_out_tensor_, cv::Scalar(114, 114, 114));
}
/*
*desctructor
*/
AnchorBaseDet::~AnchorBaseDet()
{
}
// Single-image inference preprocessing for object detection tasks
void AnchorBaseDet::pre_process(cv::Mat ori_img)
{
ScopedTiming st(model_name_ + " pre_process image", debug_mode_);
std::vector<uint8_t> chw_vec;
Utils::bgr2rgb_and_hwc2chw(ori_img, chw_vec);
Utils::padding_resize({ori_img.channels(), ori_img.rows, ori_img.cols}, chw_vec, {input_shapes_[0][3], input_shapes_[0][2]}, ai2d_out_tensor_, cv::Scalar(114, 114, 114));
}
// Using AI2D for video stream inference preprocessing in object detection tasks
void AnchorBaseDet::pre_process()
{
ScopedTiming st(model_name_ + " pre_process video", debug_mode_);
size_t isp_size = isp_shape_.channel * isp_shape_.height * isp_shape_.width;
auto buf = ai2d_in_tensor_.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_write).unwrap().buffer();
memcpy(reinterpret_cast<char *>(buf.data()), (void *)vaddr_, isp_size);
hrt::sync(ai2d_in_tensor_, sync_op_t::sync_write_back, true).expect("sync write_back failed");
ai2d_builder_->invoke(ai2d_in_tensor_, ai2d_out_tensor_).expect("error occurred in ai2d running");
}
//inference
void AnchorBaseDet::inference()
{
this->run();
this->get_output();
}
// Post-processing for object detection tasks, including parsing positions from model outputs, parsing categories, and performing NMS
void AnchorBaseDet::post_process(FrameSize frame_size, vector<ob_det_res> &results)
{
ScopedTiming st(model_name_ + " post_process", debug_mode_);
output_0 = p_outputs_[0];
output_1 = p_outputs_[1];
output_2 = p_outputs_[2];
if (nms_option)
{
vector<ob_det_res> box0, box1, box2;
box0 = decode_infer(output_0, frame_size, 0);
box1 = decode_infer(output_1, frame_size, 1);
box2 = decode_infer(output_2, frame_size, 2);
results.insert(results.begin(), box0.begin(), box0.end());
results.insert(results.begin(), box1.begin(), box1.end());
results.insert(results.begin(), box2.begin(), box2.end());
nms(results);
}
else
{
vector<vector<ob_det_res>> box0, box1, box2;
box0 = decode_infer_class(output_0, frame_size, 0);
box1 = decode_infer_class(output_1, frame_size, 1);
box2 = decode_infer_class(output_2, frame_size, 2);
for(int i = 0; i < num_class; i++)
{
box0[i].insert(box0[i].begin(), box1[i].begin(), box1[i].end());
box0[i].insert(box0[i].begin(), box2[i].begin(), box2[i].end());
nms(box0[i]);
results.insert(results.begin(), box0[i].begin(), box0[i].end());
}
}
}
vector<ob_det_res> AnchorBaseDet::decode_infer(float* data, FrameSize frame_size, int k)
{
int stride = strides[k];
float ratiow = (float)input_width / frame_size.width;
float ratioh = (float)input_height / frame_size.height;
float gain = ratiow < ratioh ? ratiow : ratioh;
std::vector<ob_det_res> result;
int grid_size_w = input_width / stride;
int grid_size_h = input_height / stride;
int one_rsize = num_class + 5;
float cx, cy, w, h;
for (int shift_y = 0; shift_y < grid_size_h; shift_y++)
{
for (int shift_x = 0; shift_x < grid_size_w; shift_x++)
{
int loc = shift_x + shift_y * grid_size_w;
for (int i = 0; i < 3; i++)
{
float* record = data + (loc * 3 + i) * one_rsize;
float* cls_ptr = record + 5;
for (int cls = 0; cls < num_class; cls++)
{
float score = (cls_ptr[cls]) * (record[4]);
if (score > ob_det_thresh)
{
cx = ((record[0]) * 2.f - 0.5f + (float)shift_x) * (float)stride;
cy = ((record[1]) * 2.f - 0.5f + (float)shift_y) * (float)stride;
w = pow((record[2]) * 2.f, 2) * anchors[k][i][0];
h = pow((record[3]) * 2.f, 2) * anchors[k][i][1];
cx -= ((input_width - frame_size.width * gain) / 2);
cy -= ((input_height - frame_size.height * gain) / 2);
cx /= gain;
cy /= gain;
w /= gain;
h /= gain;
ob_det_res box;
box.x1 = std::max(0, std::min(int(frame_size.width), int(cx - w / 2.f)));
box.y1 = std::max(0, std::min(int(frame_size.height), int(cy - h / 2.f)));
box.x2 = std::max(0, std::min(int(frame_size.width), int(cx + w / 2.f)));
box.y2 = std::max(0, std::min(int(frame_size.height), int(cy + h / 2.f)));
box.score = score;
box.label_index = cls;
box.label = labels[cls];
result.push_back(box);
}
}
}
}
}
return result;
}
vector<vector<ob_det_res>> AnchorBaseDet::decode_infer_class(float* data, FrameSize frame_size, int k)
{
int stride = strides[k];
float ratiow = (float)input_width / frame_size.width;
float ratioh = (float)input_height / frame_size.height;
float gain = ratiow < ratioh ? ratiow : ratioh;
std::vector<std::vector<ob_det_res>> result;
for (int i = 0; i < num_class; i++)
{
result.push_back(vector<ob_det_res>());// Continuously add rows to v2d
}
int grid_size_w = input_width / stride;
int grid_size_h = input_height / stride;
int one_rsize = num_class + 5;
float cx, cy, w, h;
for (int shift_y = 0; shift_y < grid_size_h; shift_y++)
{
for (int shift_x = 0; shift_x < grid_size_w; shift_x++)
{
int loc = shift_x + shift_y * grid_size_w;
for (int i = 0; i < 3; i++)
{
float* record = data + (loc * 3 + i) * one_rsize;
float* cls_ptr = record + 5;
for (int cls = 0; cls < num_class; cls++)
{
float score = (cls_ptr[cls]) * (record[4]);
if (score > ob_det_thresh)
{
cx = ((record[0]) * 2.f - 0.5f + (float)shift_x) * (float)stride;
cy = ((record[1]) * 2.f - 0.5f + (float)shift_y) * (float)stride;
w = pow((record[2]) * 2.f, 2) * anchors[k][i][0];
h = pow((record[3]) * 2.f, 2) * anchors[k][i][1];
cx -= ((input_width - frame_size.width * gain) / 2);
cy -= ((input_height - frame_size.height * gain) / 2);
cx /= gain;
cy /= gain;
w /= gain;
h /= gain;
ob_det_res box;
box.x1 = std::max(0, std::min(int(frame_size.width), int(cx - w / 2.f)));
box.y1 = std::max(0, std::min(int(frame_size.height), int(cy - h / 2.f)));
box.x2 = std::max(0, std::min(int(frame_size.width), int(cx + w / 2.f)));
box.y2 = std::max(0, std::min(int(frame_size.height), int(cy + h / 2.f)));
box.score = score;
box.label_index = cls;
box.label = labels[cls];
result[cls].push_back(box);
}
}
}
}
}
return result;
}
void AnchorBaseDet::nms(vector<ob_det_res>& input_boxes)
{
std::sort(input_boxes.begin(), input_boxes.end(), [](ob_det_res a, ob_det_res b) { return a.score > b.score; });
std::vector<float> vArea(input_boxes.size());
for (int i = 0; i < int(input_boxes.size()); ++i)
{
vArea[i] = (input_boxes.at(i).x2 - input_boxes.at(i).x1 + 1)
* (input_boxes.at(i).y2 - input_boxes.at(i).y1 + 1);
}
for (int i = 0; i < int(input_boxes.size()); ++i)
{
for (int j = i + 1; j < int(input_boxes.size());)
{
float xx1 = std::max(input_boxes[i].x1, input_boxes[j].x1);
float yy1 = std::max(input_boxes[i].y1, input_boxes[j].y1);
float xx2 = std::min(input_boxes[i].x2, input_boxes[j].x2);
float yy2 = std::min(input_boxes[i].y2, input_boxes[j].y2);
float w = std::max(float(0), xx2 - xx1 + 1);
float h = std::max(float(0), yy2 - yy1 + 1);
float inter = w * h;
float ovr = inter / (vArea[i] + vArea[j] - inter);
if (ovr >= ob_nms_thresh)
{
input_boxes.erase(input_boxes.begin() + j);
vArea.erase(vArea.begin() + j);
}
else
{
j++;
}
}
}
}
In other files, utils.h declares the tool structures and functions, and utils.cc contains the specific implementation of the tool functions; vi_vo.h is the header file for implementing video input and output; json.h is the header file for JSON file parsing, which is needed to parse the deployment configuration file deploy.json during program execution, and json.cpp contains the implementation of its interfaces; scoped_timing.hpp is a timing tool used to measure runtime.
main.cc is the main function, which implements the startup command parameter parsing and inference for static images and video streams.
/*
* Implement static image inference
*/
void image_proc_ob_det(config_args args, char *argv[])
{
// Read the image from the static image path in the parameters, create a cv::Mat
cv::Mat ori_img = cv::imread(argv[3]);
int ori_w = ori_img.cols;
int ori_h = ori_img.rows;
vector<ob_det_res> results;
// Instance initialization
AnchorBaseDet ob_det(args, argv[2], atoi(argv[4]));
// Preprocessing
ob_det.pre_process(ori_img);
// Inference
ob_det.inference();
// Postprocessing
ob_det.post_process({ori_w, ori_h}, results);
// Draw detection boxes and classes on the results
Utils::draw_ob_det_res(ori_img, results);
// Save the detection result image
cv::imwrite("result_ob_det.jpg", ori_img);
}
The following code is the process for video stream inference.
/*
* Video stream inference
*/
void video_proc_ob_det(config_args args, char *argv[])
{
// Start video capture
vivcap_start();
// Create an instance of the data structure for one frame for OSD display
k_video_frame_info vf_info;
void *pic_vaddr = NULL;
memset(&vf_info, 0, sizeof(vf_info));
// Data initialization
vf_info.v_frame.width = osd_width;
vf_info.v_frame.height = osd_height;
vf_info.v_frame.stride[0] = osd_width;
vf_info.v_frame.pixel_format = PIXEL_FORMAT_ARGB_8888;
block = vo_insert_frame(&vf_info, &pic_vaddr);
// Allocate memory
size_t paddr = 0;
void *vaddr = nullptr;
size_t size = SENSOR_CHANNEL * SENSOR_HEIGHT * SENSOR_WIDTH;
int ret = kd_mpi_sys_mmz_alloc_cached(&paddr, &vaddr, "allocate", "anonymous", size);
if (ret)
{
std::cerr << "physical_memory_block::allocate failed: ret = " << ret << ", errno = " << strerror(errno) << std::endl;
std::abort();
}
// Declare the detection result variable results, used to store detection results
vector<ob_det_res> results;
// Instance initialization
AnchorBaseDet ob_det(args, argv[2], {SENSOR_CHANNEL, SENSOR_HEIGHT, SENSOR_WIDTH}, reinterpret_cast<uintptr_t>(vaddr), reinterpret_cast<uintptr_t>(paddr), atoi(argv[4]));
// In the while loop, get one frame of the image sequentially, output and post-process it through the AI model inference process, draw the results on the OSD frame, and insert it into the display
while (!isp_stop)
{
ScopedTiming st("total time", 1);
{
ScopedTiming st("read capture", atoi(argv[4]));
// VICAP_CHN_ID_1 out rgb888p
memset(&dump_info, 0 , sizeof(k_video_frame_info));
// Dump the current frame of the camera into dump_info
ret = kd_mpi_vicap_dump_frame(vicap_dev, VICAP_CHN_ID_1, VICAP_DUMP_YUV, &dump_info, 1000);
if (ret) {
printf("sample_vicap...kd_mpi_vicap_dump_frame failed.\n");
continue;
}
}
{
// Copy the data in dump_info to the address vaddr used when instantiating AnchorBaseDet
ScopedTiming st("isp copy", atoi(argv[4]));
auto vbvaddr = kd_mpi_sys_mmap_cached(dump_info.v_frame.phys_addr[0], size);
memcpy(vaddr, (void *)vbvaddr, SENSOR_HEIGHT * SENSOR_WIDTH * 3);
kd_mpi_sys_munmap(vbvaddr, size);
}
// Clear detection results
results.clear();
// Preprocessing
ob_det.pre_process();
// Inference
ob_det.inference();
// Model output postprocessing
ob_det.post_process({SENSOR_WIDTH, SENSOR_HEIGHT}, results);
// Create OSD frame data
cv::Mat osd_frame(osd_height, osd_width, CV_8UC4, cv::Scalar(0, 0, 0, 0));
{
// Draw detection boxes and classes on one frame of the OSD
ScopedTiming st("osd draw", atoi(argv[4]));
Utils::draw_ob_det_res(osd_frame, results, {osd_width, osd_height}, {SENSOR_WIDTH, SENSOR_HEIGHT});
}
{
// Copy the data from osd_frame to pic_vaddr
ScopedTiming st("osd copy", atoi(argv[4]));
memcpy(pic_vaddr, osd_frame.data, osd_width * osd_height * 4);
// Insert frame into display channel
kd_mpi_vo_chn_insert_frame(osd_id+3, &vf_info);
printf("kd_mpi_vo_chn_insert_frame success \n");
ret = kd_mpi_vicap_dump_release(vicap_dev, VICAP_CHN_ID_1, &dump_info);
if (ret) {
printf("sample_vicap...kd_mpi_vicap_dump_release failed.\n");
}
}
}
// Release handle
vo_osd_release_block();
// Stop video capture
vivcap_stop();
// Free memory
ret = kd_mpi_sys_mmz_free(paddr, vaddr);
if (ret)
{
std::cerr << "free failed: ret = " << ret << ", errno = " << strerror(errno) << std::endl;
std::abort();
}
}
Explanation of k230_code/k230_deploy/CMakeLists.txt
This is the CMakeLists.txt script in the k230_code/k230_deploy directory, which sets the C++ files to be compiled and the name of the generated elf executable file, as follows:
set(src main.cc utils.cc ai_base.cc json.cpp anchorbase_det.cc)
set(bin main.elf)
# Add the root directory of the project to the header file search path.
include_directories(${PROJECT_SOURCE_DIR})
# Add the header file directory of the nncase RISC-V vector library
include_directories(${nncase_sdk_root}/riscv64/rvvlib/include)
# Add the user application API header file directory in the k230 SDK
include_directories(${k230_sdk}/src/big/mpp/userapps/api/)
# Add the mpp (Media Process Platform) header file directory of the k230 SDK
include_directories(${k230_sdk}/src/big/mpp/include)
# Add the header file directory related to mpp
include_directories(${k230_sdk}/src/big/mpp/include/comm)
# Add the header file directory of the sample VO (video output) application
include_directories(${k230_sdk}/src/big/mpp/userapps/sample/sample_vo)
# Add the linker search path, pointing to the directory of the nncase RISC-V vector library
link_directories(${nncase_sdk_root}/riscv64/rvvlib/)
# Create an executable file with the previously set source file list as input
add_executable(${bin} ${src})
# Set the libraries that the executable file needs to link. The list includes various libraries, including nncase-related libraries, k230 SDK libraries, and other libraries.
target_link_libraries(${bin} ...)
# Link some OpenCV-related libraries and some other third-party libraries to the executable file
target_link_libraries(${bin} opencv_imgproc opencv_imgcodecs opencv_core zlib libjpeg-turbo libopenjp2 libpng libtiff libwebp csi_cv)
# Install the generated executable file to the specified target path (bin directory)
install(TARGETS ${bin} DESTINATION bin)
Explanation of k230_code/CMakeLists.txt
cmake_minimum_required(VERSION 3.2)
project(nncase_sdk C CXX)
# Set the root directory of nncase, located under src/big/nncase, you can also set it to an absolute path
set(nncase_sdk_root "${PROJECT_SOURCE_DIR}/../../nncase/")
# Set the root directory of k230_sdk, currently obtained from the third-level parent directory of the nncase directory, you can also set it to an absolute path
set(k230_sdk ${nncase_sdk_root}/../../../)
# Set the path of the linker script, the linker script is placed under k230_code/cmake
set(CMAKE_EXE_LINKER_FLAGS "-T ${PROJECT_SOURCE_DIR}/cmake/link.lds --static")
# Set OpenCV
set(k230_opencv ${k230_sdk}/src/big/utils/lib/opencv)
include_directories(${k230_opencv}/include/opencv4/)
link_directories(${k230_opencv}/lib ${k230_opencv}/lib/opencv4/3rdparty)
# Set mmz
link_directories(${k230_sdk}/src/big/mpp/userapps/lib)
# Set nncase
include_directories(${nncase_sdk_root}/riscv64)
include_directories(${nncase_sdk_root}/riscv64/nncase/include)
include_directories(${nncase_sdk_root}/riscv64/nncase/include/nncase/runtime)
link_directories(${nncase_sdk_root}/riscv64/nncase/lib/)
# Add the subproject to be compiled
add_subdirectory(k230_deploy)
Explanation of k230_code/build_app.sh
#!/bin/bash
set -x
# Set cross build toolchain
# Add the path of the cross-compilation toolchain to the system's PATH environment variable, so that it can be used in subsequent commands. The toolchain used is the big-core compilation toolchain.
export PATH=$PATH:/opt/toolchain/riscv64-linux-musleabi_for_x86_64-pc-linux-gnu/bin/
clear
rm -rf out
mkdir out
pushd out
cmake -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=`pwd` \
-DCMAKE_TOOLCHAIN_FILE=cmake/Riscv64.cmake \
..
make -j && make install
popd
# The generated main.elf can be found in the k230_bin folder under the k230_code directory
k230_bin=`pwd`/k230_bin
rm -rf ${k230_bin}
mkdir -p ${k230_bin}
if [ -f out/bin/main.elf ]; then
cp out/bin/main.elf ${k230_bin}
fi
10.2.5.3 Code Compilation#
Copy the k230_code folder from the project to src/big/nncase under the k230_sdk directory, execute the compilation script, and compile the C++ code into the main.elf executable file.
# If you are burning Linux+RT-Smart dual system image, execute in the k230_SDK root directory
make CONF=k230_canmv_defconfig prepare_memory
# If you are burning a pure RT-Smart single system image, execute in the k230_SDK root directory
make CONF=k230_canmv_only_rtt_defconfig prepare_memory
# Return to the current project directory and grant permissions
chmod +x build_app.sh
./build_app.sh
10.2.5.4 Prepare ELF Files#
The files needed for the subsequent deployment steps include:
k230_code/k230_bin/main.elf;
10.2.6 Network Configuration and File Copy#
There are three ways to copy the files to be used to the development board.
10.2.6.1 Offline File Copy#
Note: This method is applicable to Linux+RT-Smart dual-system image and pure RT-Smart single-system image;
By inserting and removing the SD card, copy the required files to the appropriate location. The root directory of the SD card is mapped to the /sharefs directory of both the small and large cores.
10.2.6.2 TFTP File Transfer#
Note: This method is only applicable to Linux+RT-Smart dual-system images; for pure RT-Smart single system, please use the offline copy method;
Windows System PC Network Configuration
Control Panel -> Network and Sharing Center -> Change adapter settings -> Ethernet card -> Right-click Properties -> Select (TCP/IPv4) -> Properties
Configure IP address, subnet mask, gateway, and DNS server address:
Development Board Network Configuration
Enter the small core command line and execute:
# Check if eth0 exists
ifconfig
# Configure the development board IP to be in the same subnet as the PC
ifconfig eth0 192.168.1.22
# Check IP configuration
ifconfig
Tool: tftpd64
Install the tftp communication tool, download link: https://bitbucket.org/phjounin/tftpd64/downloads/
Start tftpd64 and configure the directory for storing files to be transferred and the service network card.
Explanation of sharefs
# Enter the root directory of the small core
cd /
# View directories
ls
# The sharefs directory is a shared directory for both the small and large cores, so files copied to the sharefs directory from the small core are also visible to the large core.
File Transfer
# The following code is executed in the small core serial port
# Transfer files from the directory configured in tftpd64 on the PC to the current directory on the development board
tftp -g -r your_file 192.168.1.2
# Transfer files from the current directory on the development board to the directory configured in tftpd64 on the PC
tftp -p -r board_file 192.168.1.2
10.2.6.2 SCP File Transfer#
Note: This method is only applicable to Linux+RT-Smart dual-system images; for pure RT-Smart single system, please use the offline copy method;
In a Linux system, with the PC normally connected to the network, the development board can connect to other network ports under the same gateway as the PC via an Ethernet cable, and file transfer can be achieved using the scp command.
Power on the development board and enter the COM interface for both the small and large cores. Execute the scp transfer command in the small core:
# Copy files from the PC to the development board
scp username@hostname_or_IP:source_directory destination_directory_on_board
# Copy folders
scp -r username@hostname_or_IP:source_directory destination_directory_on_board
# Copy files from the development board to the PC
scp source_directory_on_board username@hostname_or_IP:destination_directory_on_PC
# Copy folders
scp -r source_directory_on_board username@hostname_or_IP:destination_directory_on_PC
10.2.7 K230-side Deployment#
10.2.7.1 Board-side Deployment Process#
According to the file copying process provided in the previous section, copy the files prepared for the model training and testing part and the elf file prepared for the C++ code compilation part to the development board. The Linux+RT-Smart dual system is in /sharefs, and the pure RT-Smart is in /sdcard. Create a folder test_det:
test_det
├──best.kmodel
├──deploy.json
├──main.elf
├──test.jpg
To perform static image inference, execute the following code (Note: The code needs to be executed in the large core):
# Linux+RT-Smart
cd /sharefs/test_cls
# Only RT-Smart
cd /sdcard/test_cls
"Model inference parameter explanation: <config_file> <kmodel_det> <input_mode> <debug_mode>"
"Options:"
" config_file JSON configuration file for deployment, default is deploy_config.json"
" kmodel_det Path to the kmodel"
" input_mode Local image (image path) / Camera (None)"
" debug_mode Whether debugging is needed, 0, 1, 2 represent no debugging, simple debugging, and detailed debugging"
main.elf deploy.json best.kmodel test.jpg 2
For camera video stream inference, execute the following code:
main.elf deploy.json best.kmodel None 2
10.2.7.2 Board Deployment Results#
Static image inference illustration:

Video stream inference illustration:
