K230 nncase Development Guide#

Copyright 2023 Canaan Inc. ©
Disclaimer#
The products, services or features you purchase should be subject to Canaan Inc. (“Company”, hereinafter referred to as “Company”) and its affiliates are bound by the commercial contracts and terms and conditions of all or part of the products, services or features described in this document may not be covered by your purchase or use. Unless otherwise agreed in the contract, the Company does not provide any express or implied representations or warranties as to the correctness, reliability, completeness, merchantability, fitness for a particular purpose and non-infringement of any statements, information, or content in this document. Unless otherwise agreed, this document is intended as a guide for use only.
Due to product version upgrades or other reasons, the content of this document may be updated or modified from time to time without any notice.
Trademark Notice#
![]() , “Canaan” and other Canaan trademarks are trademarks of Canaan Inc. and its affiliates. All other trademarks or registered trademarks that may be mentioned in this document are owned by their respective owners.
, “Canaan” and other Canaan trademarks are trademarks of Canaan Inc. and its affiliates. All other trademarks or registered trademarks that may be mentioned in this document are owned by their respective owners.
Copyright 2023 Canaan Inc.. © All Rights Reserved. Without the written permission of the company, no unit or individual may extract or copy part or all of the content of this document without authorization, and shall not disseminate it in any form.
Directory#
[TOC]
preface#
Overview#
This document is the K230 nncase user description document, providing users with how to install nncase, how to call compiler APIs to compile neural network models and runtime APIs to write AI inference programs.
Reader object#
This document (this guide) is intended primarily for:
Technical Support Engineer
Software Development Engineer
Definition of acronyms#
abbreviation |
description |
|---|---|
PTQ |
Post-training quantization |
MSE |
mean-square error |
Revision history#
Document version number |
Modify the description |
Author |
date |
|---|---|---|---|
V1.0 |
First version of the document |
Yang Zhang/Chenghai Huo |
2023/4/7 |
V1.1 |
Uniformly change to word format, improve AI2D |
Yang Zhang/Chenghai Huo |
2023/5/5 |
V1.2 |
New architecture for nncase v2 |
Yang Zhang/Qihang Zheng/Chenghai Huo |
2023/6/2 |
V1.3 |
nncase_k230_v2.1.0, ai2d/runtime_tensor supports physical addresses |
Yang Zhang |
2023/7/3 |
1. Overview#
1.1 What is nncase#
nncase is a neural network compiler designed for AI accelerators, and currently supports targets such as CPU/K210/K510/K230.
Features provided by nncase
Support multiple-input multiple-output network, support multi-branch structure
Static memory allocation, no heap memory required
Operator merging and optimization
Supports float and uint8/int8 quantized inference
Supports post-training quantization, using floating-point models and quantization calibration sets
Flat model with zero-copy loading
Neural network model formats supported by nncase
tflite
onnx
1.2 nncase architecture#
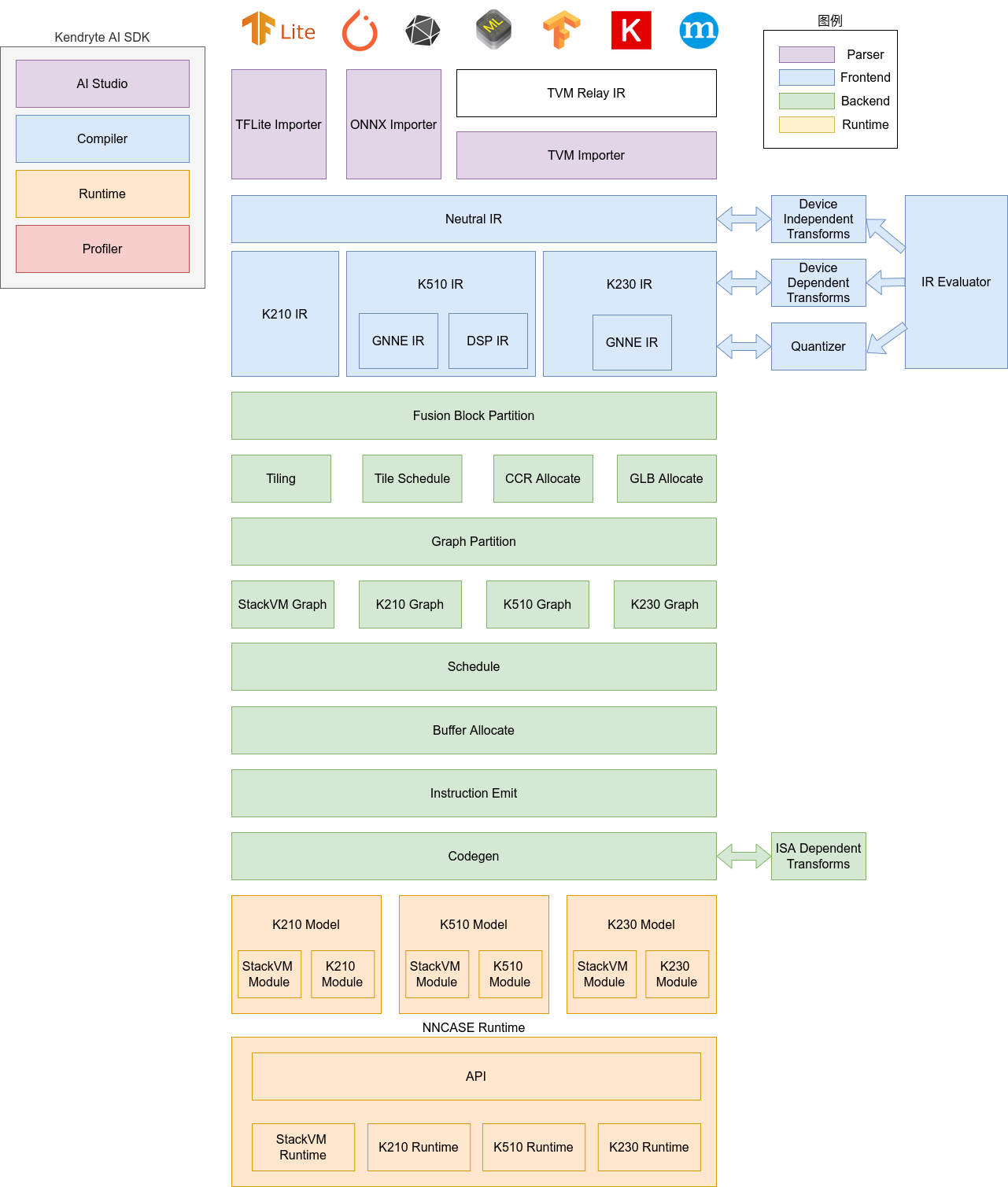
The nncase software stack consists of two parts: compiler and runtime.
Compiler: Used to compile a neural network model on a PC and finally generate a kmodel file. It mainly includes importer, IR, Evaluator, Quantize, Transform optimization, Tiling, Partition, Schedule, Codegen and other modules.
Importer: Import models from other neural network frameworks into nncase
IR: Intermediate representation, divided into Neutral IR imported by importer (device-independent) and Target IR (device-dependent) generated by Neutral IR through lower conversion
Evaluator: Evaluator provides IR interpretation execution capabilities and is often used in scenarios such as Constant Folding/PTQ Calibration
Transform: Used for IR conversion and graph traversal optimization, etc
Quantize: Quantize after training, add quantization tags to the tensor to be quantized, call Evaluator to interpret and execute according to the input correction set, collect the data range of tensor, insert quantization/dequantization nodes, and finally optimize to eliminate unnecessary quantization/dequantization nodes
Tiling: Limited by the low memory capacity of NPU, large chunks of computation need to be split. In addition, selecting the Tiling parameter when there is a large amount of data multiplexing will affect the delay and bandwidth
Partition: Divide the graph according to ModuleType, each subgraph after splitting will correspond to the RuntimeModule, and different types of RuntimeModule will correspond to different Devices (cpu/K230)
Schedule: Generates a calculation order and allocates Buffers based on data dependencies in the optimized graph
Codegen: Call the codegen corresponding to ModuleType for each subgraph to generate a RuntimeModule
Runtime: Integrated in the user app, it provides functions such as loading kmodel/setting input data/KPU execution/obtaining output data.
1.3 Development Environment#
1.3.1 Operating System#
Supported operating systems include Ubuntu 18.04/Ubuntu 20.04
1.3.2 Software Environment#
serial number |
Software |
Version number |
|---|---|---|
1 |
python |
3.6/3.7/3.8/3.9/3.10 |
2 |
pip |
>=20.3 |
3 |
numpy |
1.19.5 |
4 |
onnx |
1.9.0 |
5 |
onnx-simplifier |
0.3.6 |
6 |
Onnxoptimizer |
0.2.6 |
7 |
Onnxruntime |
1.8.0 |
8 |
dotnet-runtime |
7.0 |
1.3.3 Hardware Environment#
K230 evb
2. Compiling Model APIs (Python)#
nncase provides Python APIs for compiling neural network models on a PC
2.1 Supported operators#
2.1.1 tflite arithmetic#
Operator |
Is Supported |
|---|---|
ABS |
Yes |
ADD |
Yes |
ARG_MAX |
Yes |
ARG_MIN |
Yes |
AVERAGE_POOL_2D |
Yes |
BATCH_MATMUL |
Yes |
CAST |
Yes |
CEIL |
Yes |
CONCATENATION |
Yes |
CONV_2D |
Yes |
COS |
Yes |
CUSTOM |
Yes |
DEPTHWISE_CONV_2D |
Yes |
DIV |
Yes |
EQUAL |
Yes |
EXP |
Yes |
EXPAND_DIMS |
Yes |
FLOOR |
Yes |
FLOOR_DIV |
Yes |
FLOOR_MOD |
Yes |
FULLY_CONNECTED |
Yes |
GREATER |
Yes |
GREATER_EQUAL |
Yes |
L2_NORMALIZATION |
Yes |
LEAKY_RELU |
Yes |
LESS |
Yes |
LESS_EQUAL |
Yes |
LOG |
Yes |
LOGISTIC |
Yes |
MAX_POOL_2D |
Yes |
MAXIMUM |
Yes |
MEAN |
Yes |
MINIMUM |
Yes |
MUL |
Yes |
NEG |
Yes |
NOT_EQUAL |
Yes |
PAD |
Yes |
PADV2 |
Yes |
MIRROR_PAD |
Yes |
PACK |
Yes |
POW |
Yes |
REDUCE_MAX |
Yes |
REDUCE_MIN |
Yes |
REDUCE_PROD |
Yes |
RELU |
Yes |
PRELU |
Yes |
RELU6 |
Yes |
RESHAPE |
Yes |
RESIZE_BILINEAR |
Yes |
RESIZE_NEAREST_NEIGHBOR |
Yes |
ROUND |
Yes |
RSQRT |
Yes |
SHAPE |
Yes |
SIN |
Yes |
SLICE |
Yes |
SOFTMAX |
Yes |
SPACE_TO_BATCH_ND |
Yes |
SQUEEZE |
Yes |
BATCH_TO_SPACE_ND |
Yes |
STRIDED_SLICE |
Yes |
SQRT |
Yes |
SQUARE |
Yes |
SUB |
Yes |
SUM |
Yes |
TANH |
Yes |
TILE |
Yes |
TRANSPOSE |
Yes |
TRANSPOSE_CONV |
Yes |
QUANTIZE |
Yes |
FAKE_QUANT |
Yes |
DEQUANTIZE |
Yes |
GATHER |
Yes |
GATHER_ND |
Yes |
ONE_HOT |
Yes |
SQUARED_DIFFERENCE |
Yes |
LOG_SOFTMAX |
Yes |
SPLIT |
Yes |
HARD_SWISH |
Yes |
2.1.2 ONNX arithmetic#
Operator |
Is Supported |
|---|---|
Abs |
Yes |
Acos |
Yes |
Acosh |
Yes |
And |
Yes |
ArgMax |
Yes |
ArgMin |
Yes |
Asin |
Yes |
Asinh |
Yes |
Add |
Yes |
AveragePool |
Yes |
BatchNormalization |
Yes |
Cast |
Yes |
Ceil |
Yes |
Celu |
Yes |
Clip |
Yes |
Compress |
Yes |
Concat |
Yes |
Constant |
Yes |
ConstantOfShape |
Yes |
Conv |
Yes |
ConvTranspose |
Yes |
Cos |
Yes |
Cosh |
Yes |
CumSum |
Yes |
DepthToSpace |
Yes |
DequantizeLinear |
Yes |
Div |
Yes |
Dropout |
Yes |
Elu |
Yes |
Exp |
Yes |
Expand |
Yes |
Equal |
Yes |
Erf |
Yes |
Flatten |
Yes |
Floor |
Yes |
Gather |
Yes |
GatherElements |
Yes |
GatherND |
Yes |
Gemm |
Yes |
GlobalAveragePool |
Yes |
GlobalMaxPool |
Yes |
Greater |
Yes |
GreaterOrEqual |
Yes |
GRU |
Yes |
Hardmax |
Yes |
HardSigmoid |
Yes |
HardSwish |
Yes |
Identity |
Yes |
InstanceNormalization |
Yes |
LayerNormalization |
Yes |
LpNormalization |
Yes |
LeakyRelu |
Yes |
Less |
Yes |
LessOrEqual |
Yes |
Log |
Yes |
LogSoftmax |
Yes |
LRN |
Yes |
LSTM |
Yes |
MatMul |
Yes |
MaxPool |
Yes |
Max |
Yes |
Min |
Yes |
Mul |
Yes |
Neg |
Yes |
Not |
Yes |
OneHot |
Yes |
Pad |
Yes |
Pow |
Yes |
PRelu |
Yes |
QuantizeLinear |
Yes |
RandomNormal |
Yes |
RandomNormalLike |
Yes |
RandomUniform |
Yes |
RandomUniformLike |
Yes |
ReduceL1 |
Yes |
ReduceL2 |
Yes |
ReduceLogSum |
Yes |
ReduceLogSumExp |
Yes |
ReduceMax |
Yes |
ReduceMean |
Yes |
ReduceMin |
Yes |
ReduceProd |
Yes |
ReduceSum |
Yes |
ReduceSumSquare |
Yes |
Relu |
Yes |
Reshape |
Yes |
Resize |
Yes |
ReverseSequence |
Yes |
RoiAlign |
Yes |
Round |
Yes |
Rsqrt |
Yes |
Selu |
Yes |
Shape |
Yes |
Sign |
Yes |
Sin |
Yes |
Sinh |
Yes |
Sigmoid |
Yes |
Size |
Yes |
Slice |
Yes |
Softmax |
Yes |
Softplus |
Yes |
Softsign |
Yes |
SpaceToDepth |
Yes |
Split |
Yes |
Sqrt |
Yes |
Squeeze |
Yes |
Sub |
Yes |
Sum |
Yes |
Tanh |
Yes |
Tile |
Yes |
TopK |
Yes |
Transpose |
Yes |
Trilu |
Yes |
ThresholdedRelu |
Yes |
Upsample |
Yes |
Unsqueeze |
Yes |
Where |
Yes |
2.2 APIs#
Currently, the compiled model APIs support deep learning models in TFLITE/ONNX/Caffe and other formats.
2.2.1 CompileOptions#
【Description】
The CompileOptions class, which configures nncase compilation options
【Definition】
class CompileOptions:
benchmark_only: bool
dump_asm: bool
dump_dir: str
dump_ir: bool
swapRB: bool
input_range: List[float]
input_shape: List[int]
input_type: str
is_fpga: bool
mean: List[float]
std: List[float]
output_type: str
preprocess: bool
quant_type: str
target: str
w_quant_type: str
use_mse_quant_w: bool
input_layout: str
output_layout: str
letterbox_value: float
tcu_num: int
def __init__(self) -> None:
self.benchmark_only = False
self.dump_asm = True
self.dump_dir = "tmp"
self.dump_ir = False
self.is_fpga = False
self.quant_type = "uint8"
self.target = "cpu"
self.w_quant_type = "uint8"
self.use_mse_quant_w = True
self.tcu_num = 0
self.preprocess = False
self.swapRB = False
self.input_range = []
self.input_shape = []
self.input_type = "float32"
self.mean = [0, 0, 0]
self.std = [1, 1, 1]
self.input_layout = ""
self.output_layout = ""
self.letterbox_value = 0
【Attributes】
name |
type |
description |
|---|---|---|
dump_asm |
bool |
Specifies whether to dump the asm assembly file, which defaults to True |
dump_dir |
bool |
After specifying the dump_ir and other switches earlier, specify the dump directory here, which defaults to “tmp” |
dump_ir |
bool |
Specifies whether to dump IR, which defaults to False |
swapRB |
bool |
Whether to exchange RGB input data red and blue channels (RGB–>BGR or BGR–>RGB), the default is False |
input_range |
list |
After the input data is dequantized, the range corresponding to the floating-point number is defaulted |
input_shape |
list |
Specify the shape of the input data, the layout of the input_shape needs to be consistent with the input layout, and the letterbox operation (resize/pad, etc.) will be performed when the input_shape of the input data is inconsistent with the input shape of the model. |
input_type |
string |
Specifies the type of input data, defaulting to ‘float32’ |
mean |
list |
Pre-processing normalized parameter mean, defaulted |
Std |
list |
Pre-process normalized parameter variance, defaulted to |
output_type |
string |
Specify the type of output data, e.g. ‘float32’, ‘uint8’ (only for specifying quantization) |
preprocess |
bool |
If pre-processing is enabled, the default value is False |
target |
string |
Specify the compilation target, such as ‘k210’, ‘k510’, ‘k230’ |
letterbox_value |
float |
Specifies the padding value of the pre-processing letterbox |
input_layout |
string |
Specify the layout of the input data, such as ‘NCHW’, ‘NHWC’. If the layout of the input data is different from the layout of the model itself, nncase will insert transpose for conversion |
output_layout |
string |
Specify the layout of the output data, such as ‘NCHW’, ‘NHWC’. If the layout of the output data is different from the layout of the model itself, nncase will insert transpose for conversion. |
【Note】
input range is the range of floating-point numbers, that is, if the input data type is uint8, input range is the range after dequantization to floating-point (can not be 0~1), which can be freely specified.
input_shape needs to be specified according to the input_layout. Take
[1,224,224,3]for example. If the input_layout is NCHW, the input_shape needs to be specified[1,3,224,224]. If input_layout is NHWC, the input_shape needs to be specified as[1,224,224,3]mean and std are parameters for normalize floating-point numbers, which users can freely specify.
When using the letterbox function, you need to limit the input size to 1.5MB, and the size of a single channel to 0.75MB.
For example:
The input data type is uint8, input_range set to
[0,255], then the function of dequantization is only to perform type conversion, convert the data of uint8 to float32, and the mean and std parameters can still be specified according to the data of 0~255If the input data type is uint8 and input_range is
[0,1], the[0,1]fixed-point number will be dequantized to a floating-point number of[0,1], mean and std need to be specified according to the new floating-point range.
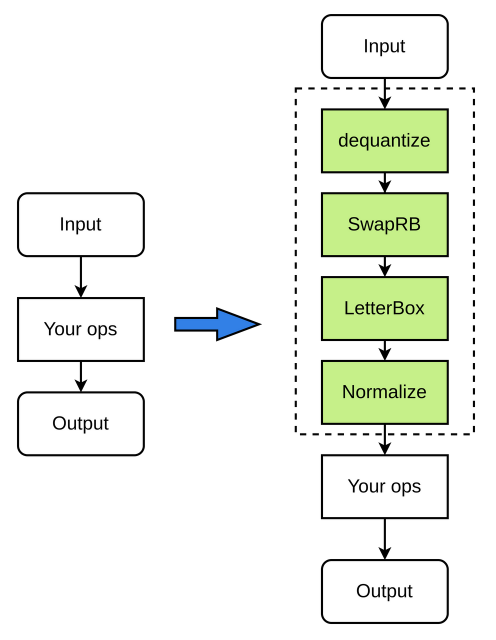
The pre-processing process is as follows (all green nodes in the figure are optional):
【Example】
Instantiate CompileOptions to configure the values of each property
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.preprocess = True
compile_options.swapRB = False
compile_options.input_shape = input_shape
compile_options.input_type = 'uint8'
compile_options.input_range = [0, 255]
compile_options.mean = [127.5, 127.5, 127.5]
compile_options.std = [127.5, 127.5, 127.5]
compile_options.input_layout = 'NCHW'
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
2.2.2 ImportOptions#
【Description】
The ImportOptions class, which configures nncase import options
【Definition】
class ImportOptions:
def __init__(self) -> None:
pass
【Example】
Instantiate ImportOptions to configure the values of each property
#import_options
import_options = nncase.ImportOptions()
2.2.3 PTQTensorOptions#
【Description】
The PTQTensorOptions class, which is used to configure nncase PTQ options
【Definition】
class PTQTensorOptions:
calibrate_method: str
input_mean: float
input_std: float
samples_count: int
quant_type: str
w_quant_type: str
finetune_weights_method: str
use_mix_quant: bool
quant_scheme: str
export_quant_scheme: bool
export_weight_range_by_channel: bool
cali_data: List[RuntimeTensor]
def __init__(self) -> None:
self.calibrate_method: str = "Kld"
self.input_mean: float = 0.5
self.input_std: float = 0.5
self.samples_count: int = 5
self.quant_type: str = "uint8"
self.w_quant_type: str = "uint8"
self.finetune_weights_method: str = "NoFineTuneWeights"
self.use_mix_quant: bool = False
self.quant_scheme: str = ""
self.export_quant_scheme: bool = False
self.export_weight_range_by_channel: bool = False
self.cali_data: List[RuntimeTensor] = []
def set_tensor_data(self, data: List[List[np.ndarray]]) -> None:
reshape_data = list(map(list, zip(*data)))
self.cali_data = [RuntimeTensor.from_numpy(
d) for d in itertools.chain.from_iterable(reshape_data)]
【Attributes】
name |
type |
description |
|---|---|---|
calibrate_method |
string |
Calibration method , supports ‘NoClip’, ‘Kld’, default value is ‘Kld’ |
input_mean |
float |
The user specifies the mean of the input, default value of 0.5 |
input_std |
float |
The user specifies the variance of the input, default value of 0.5 |
samples_count |
Int |
Number of samples |
quant_type |
string |
Specify the data quantization type, such as ‘uint8’, ‘int8’, the default value is ‘uint8’ |
w_quant_type |
string |
Specify the weight quantization type, such as ‘uint8’, ‘int8’, the default value is ‘uint8’ |
finetune_weights_method |
string |
Adjust the weight methods, there are ‘NoFineTuneWeights’, ‘UseSquant’, the default value is ‘NoFineTuneWeights’ |
use_mix_quant |
bool |
Whether to use hybrid quantization, the default value is False |
【Example】
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = 6
ptq_options.set_tensor_data(generate_data(input_shape, ptq_options.samples_count, args.dataset))
compiler.use_ptq(ptq_options)
2.2.4 set_tensor_data#
【Description】
Set the tensor data
【Definition】
def set_tensor_data(self, data: List[List[np.ndarray]]) -> None:
reshape_data = list(map(list, zip(*data)))
self.cali_data = [RuntimeTensor.from_numpy(
d) for d in itertools.chain.from_iterable(reshape_data)]
【Parameters】
name |
type |
description |
|---|---|---|
data |
List[List[np.ndarray] |
calibration data |
【Return value】
None
【Example】
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = 6
ptq_options.set_tensor_data(generate_data(input_shape, ptq_options.samples_count, args.dataset))
compiler.use_ptq(ptq_options)
2.2.5 Compiler#
【Description】
Compiler class is used to compile neural network models
【Definition】
class Compiler:
_target: _nncase.Target
_session: _nncase.CompileSession
_compiler: _nncase.Compiler
_compile_options: _nncase.CompileOptions
_quantize_options: _nncase.QuantizeOptions
_module: IRModule
2.2.6 import_tflite#
【Description】
Import the tflite model
【Definition】
def import_tflite(self, model_content: bytes, options: ImportOptions) -> None:
self._compile_options.input_format = "tflite"
self._import_module(model_content)
【Parameters】
name |
type |
description |
|---|---|---|
model_content |
byte[] |
Read the model content |
import_options |
ImportOptions |
Import options |
【Return value】
None
【Example】
model_content = read_model_file(model)
compiler.import_tflite(model_content, import_options)
2.2.7 import_onnx#
【Description】
Import the ONNX model
【Definition】
def import_onnx(self, model_content: bytes, options: ImportOptions) -> None:
self._compile_options.input_format = "onnx"
self._import_module(model_content)
【Parameters】
name |
type |
description |
|---|---|---|
model_content |
byte[] |
Read the model content |
import_options |
ImportOptions |
Import options |
【Return value】
None
【Example】
model_content = read_model_file(model)
compiler.import_onnx(model_content, import_options)
2.2.8 use_ptq#
【Description】
Set PTQ configuration options.
The K230 must use quantization by default.
【Definition】
use_ptq(ptq_options)
【Parameters】
name |
type |
description |
|---|---|---|
ptq_options |
PTQTensorOptions |
PTQ configuration options |
【Return value】 None
【Example】
compiler.use_ptq(ptq_options)
2.2.9 compile#
【Description】
Compile the neural network model
【Definition】
compile()
【Parameters】
None
【Return value】
None
【Example】
compiler.compile()
2.2.10 gencode_tobytes#
【Description】
Generate a kmodel byte stream
【Definition】
gencode_tobytes()
【Parameters】
None
【Return value】
bytes[]
【Example】
kmodel = compiler.gencode_tobytes()
with open(os.path.join(infer_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
2.3 Examples#
The model and python compilation script used in the following example
The original model files are located in the /path/to/k230_sdk/src/big/nncase/examples/models directory
Python compilation scripts are located in the /path/to/k230_sdk/src/big/nncase/examples/scripts directory
2.3.1 Compiling the tflite model#
mbv2_tflite.py is following
import os
import argparse
import numpy as np
from PIL import Image
import nncase
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def generate_data(shape, batch, calib_dir):
img_paths = [os.path.join(calib_dir, p) for p in os.listdir(calib_dir)]
data = []
for i in range(batch):
assert i < len(img_paths), "calibration images not enough."
img_data = Image.open(img_paths[i]).convert('RGB')
img_data = img_data.resize((shape[3], shape[2]), Image.BILINEAR)
img_data = np.asarray(img_data, dtype=np.uint8)
img_data = np.transpose(img_data, (2, 0, 1))
data.append([img_data[np.newaxis, ...]])
return data
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
parser.add_argument("--dataset", type=str, help='calibration_dataset')
args = parser.parse_args()
input_shape = [1, 3, 224, 224]
dump_dir = 'tmp/mbv2_tflite'
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.preprocess = True
compile_options.swapRB = False
compile_options.input_shape = input_shape
compile_options.input_type = 'uint8'
compile_options.input_range = [0, 255]
compile_options.mean = [127.5, 127.5, 127.5]
compile_options.std = [127.5, 127.5, 127.5]
compile_options.input_layout = 'NCHW'
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import
model_content = read_model_file(args.model)
import_options = nncase.ImportOptions()
compiler.import_tflite(model_content, import_options)
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = 6
ptq_options.set_tensor_data(generate_data(input_shape, ptq_options.samples_count, args.dataset))
compiler.use_ptq(ptq_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()
Run the following command to compile the tflite model of mobilenetv2, and the target is k230
root@c285a41a7243:/mnt/# cd src/big/nncase/examples
root@c285a41a7243:/mnt/src/big/nncase/examples# python3 ./scripts/mbv2_tflite.py --target k230 --model models/mbv2.tflite --dataset calibration_dataset
2.3.2 Compiling the ONNX model#
For onnx models, it is recommended to use ONNX Simplifier for simplification before compiling with nncase
yolov5s_onnx.py is following
import os
import argparse
import numpy as np
from PIL import Image
import onnxsim
import onnx
import nncase
def parse_model_input_output(model_file):
onnx_model = onnx.load(model_file)
input_all = [node.name for node in onnx_model.graph.input]
input_initializer = [node.name for node in onnx_model.graph.initializer]
input_names = list(set(input_all) - set(input_initializer))
input_tensors = [
node for node in onnx_model.graph.input if node.name in input_names]
# input
inputs = []
for _, e in enumerate(input_tensors):
onnx_type = e.type.tensor_type
input_dict = {}
input_dict['name'] = e.name
input_dict['dtype'] = onnx.mapping.TENSOR_TYPE_TO_NP_TYPE[onnx_type.elem_type]
input_dict['shape'] = [(i.dim_value if i.dim_value != 0 else d) for i, d in zip(
onnx_type.shape.dim, [1, 3, 224, 224])]
inputs.append(input_dict)
return onnx_model, inputs
def onnx_simplify(model_file, dump_dir):
onnx_model, inputs = parse_model_input_output(model_file)
onnx_model = onnx.shape_inference.infer_shapes(onnx_model)
input_shapes = {}
for input in inputs:
input_shapes[input['name']] = input['shape']
onnx_model, check = onnxsim.simplify(onnx_model, input_shapes=input_shapes)
assert check, "Simplified ONNX model could not be validated"
model_file = os.path.join(dump_dir, 'simplified.onnx')
onnx.save_model(onnx_model, model_file)
return model_file
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def generate_data_ramdom(shape, batch):
data = []
for i in range(batch):
data.append([np.random.randint(0, 256, shape).astype(np.uint8)])
return data
def generate_data(shape, batch, calib_dir):
img_paths = [os.path.join(calib_dir, p) for p in os.listdir(calib_dir)]
data = []
for i in range(batch):
assert i < len(img_paths), "calibration images not enough."
img_data = Image.open(img_paths[i]).convert('RGB')
img_data = img_data.resize((shape[3], shape[2]), Image.BILINEAR)
img_data = np.asarray(img_data, dtype=np.uint8)
img_data = np.transpose(img_data, (2, 0, 1))
data.append([img_data[np.newaxis, ...]])
return data
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
parser.add_argument("--dataset", type=str, help='calibration_dataset')
args = parser.parse_args()
input_shape = [1, 3, 320, 320]
dump_dir = 'tmp/yolov5s_onnx'
if not os.path.exists(dump_dir):
os.makedirs(dump_dir)
# onnx simplify
model_file = onnx_simplify(args.model, dump_dir)
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.preprocess = True
compile_options.swapRB = False
compile_options.input_shape = input_shape
compile_options.input_type = 'uint8'
compile_options.input_range = [0, 255]
compile_options.mean = [0, 0, 0]
compile_options.std = [255, 255, 255]
compile_options.input_layout = 'NCHW'
compile_options.output_layout = 'NCHW'
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import
model_content = read_model_file(model_file)
import_options = nncase.ImportOptions()
compiler.import_onnx(model_content, import_options)
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = 6
ptq_options.set_tensor_data(generate_data(input_shape, ptq_options.samples_count, args.dataset))
compiler.use_ptq(ptq_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()
Run the following command to compile the ONNX model with a target of K230
root@c285a41a7243:/mnt/# cd src/big/nncase/examples
root@c285a41a7243: /mnt/src/big/nncase/examples # python3 ./scripts/yolov5s_onnx.py --target k230 --model models/yolov5s.onnx --dataset calibration_dataset
3. Simulator APIs (Python)#
In addition to compiling model APIs, nncase also provides APIs for inference models, kmodels generated by inference compilation models on PC, and is used to verify whether nncase inference results are consistent with the runtime results of the corresponding deep learning framework.
3.1 APIs#
3.1.1 MemoryRange#
【Description】
The MemoryRange class, which represents a range of memory
【Definition】
py::class_<memory_range>(m, "MemoryRange")
.def_readwrite("location", &memory_range::memory_location)
.def_property(
"dtype", [](const memory_range &range) { return to_dtype(range.datatype); },
[](memory_range &range, py::object dtype) { range.datatype = from_dtype(py::dtype::from_args(dtype)); })
.def_readwrite("start", &memory_range::start)
.def_readwrite("size", &memory_range::size);
【Attributes】
name |
type |
description |
|---|---|---|
location |
Int |
Memory location, 0 means input, 1 means output, 2 means rdata, 3 represents data, and 4 represents shared_data |
dtype |
Python data types |
data type |
start |
Int |
Memory start address |
Size |
Int |
Memory size |
【Example】
mr = nncase.MemoryRange()
3.1.2 RuntimeTensor#
【Description】
The RuntimeTensor class, which is used to represent runtime tensor
【Definition】
py::class_<runtime_tensor>(m, "RuntimeTensor")
.def_static("from_numpy", [](py::array arr) {
auto src_buffer = arr.request();
auto datatype = from_dtype(arr.dtype());
auto tensor = host_runtime_tensor::create(
datatype,
to_rt_shape(src_buffer.shape),
to_rt_strides(src_buffer.itemsize, src_buffer.strides),
gsl::make_span(reinterpret_cast<gsl::byte *>(src_buffer.ptr), src_buffer.size * src_buffer.itemsize),
[=](gsl::byte *) { arr.dec_ref(); })
.unwrap_or_throw();
arr.inc_ref();
return tensor;
})
.def("copy_to", [](runtime_tensor &from, runtime_tensor &to) {
from.copy_to(to).unwrap_or_throw();
})
.def("to_numpy", [](runtime_tensor &tensor) {
auto host = tensor.as_host().unwrap_or_throw();
auto src_map = std::move(hrt::map(host, hrt::map_read).unwrap_or_throw());
auto src_buffer = src_map.buffer();
return py::array(
to_dtype(tensor.datatype()),
tensor.shape(),
to_py_strides(runtime::get_bytes(tensor.datatype()), tensor.strides()),
src_buffer.data());
})
.def_property_readonly("dtype", [](runtime_tensor &tensor) {
return to_dtype(tensor.datatype());
})
.def_property_readonly("shape", [](runtime_tensor &tensor) {
return to_py_shape(tensor.shape());
});
【Attributes】
name |
type |
description |
|---|---|---|
dtype |
Python data types |
The data type of Tensor |
shape |
list |
The shape of tensor |
3.1.3 from_numpy#
【Description】
Construct a RuntimeTensor object from numpy.ndarray
【Definition】
from_numpy(py::array arr)
【Parameters】
name |
type |
description |
|---|---|---|
Arr |
numpy.ndarray |
numpy.ndarray object |
【Return value】
RuntimeTensor
【Example】
tensor = nncase.RuntimeTensor.from_numpy(self.inputs[i]['data'])
3.1.4 copy_to#
【Description】
拷贝RuntimeTensor
【Definition】
copy_to(RuntimeTensor to)
【Parameters】
name |
type |
description |
|---|---|---|
to |
RuntimeTensor |
RuntimeTensor对象 |
【Return value】
None
【Example】
sim.get_output_tensor(i).copy_to(to)
3.1.5 to_numpy#
【Description】
Convert the RuntimeTensor to a numpy.ndarray object
【Definition】
to_numpy()
【Parameters】
None
【Return value】
numpy.ndarray object
【Example】
arr = sim.get_output_tensor(i).to_numpy()
3.1.6 Simulator#
【Description】
Simulator class is used to simulate kmodels on a PC
【Definition】
py::class_<interpreter>(m, "Simulator")
.def(py::init())
.def("load_model", [](interpreter &interp, gsl::span<const gsl::byte> buffer) { interp.load_model(buffer).unwrap_or_throw(); })
.def_property_readonly("inputs_size", &interpreter::inputs_size)
.def_property_readonly("outputs_size", &interpreter::outputs_size)
.def("get_input_desc", &interpreter::input_desc)
.def("get_output_desc", &interpreter::output_desc)
.def("get_input_tensor", [](interpreter &interp, size_t index) { return interp.input_tensor(index).unwrap_or_throw(); })
.def("set_input_tensor", [](interpreter &interp, size_t index, runtime_tensor tensor) { return interp.input_tensor(index, tensor).unwrap_or_throw(); })
.def("get_output_tensor", [](interpreter &interp, size_t index) { return interp.output_tensor(index).unwrap_or_throw(); })
.def("set_output_tensor", [](interpreter &interp, size_t index, runtime_tensor tensor) { return interp.output_tensor(index, tensor).unwrap_or_throw(); })
.def("run", [](interpreter &interp) { interp.run().unwrap_or_throw(); });
【Attributes】
name |
type |
description |
|---|---|---|
inputs_size |
Int |
Number of inputs |
outputs_size |
Int |
Number of outputs |
【Example】
sim = nncase.Simulator()
3.1.7 load_model#
【Description】
Load kmodel
【Definition】
load_model(model_content)
【Parameters】
name |
type |
description |
|---|---|---|
model_content |
byte[] |
kmodel byte stream |
【Return value】
None
【Example】
sim.load_model(kmodel)
3.1.8 get_input_desc#
【Description】
Gets the description of the input for the specified index
【Definition】
get_input_desc(index)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
The index of the input |
【Return value】
MemoryRange
【Example】
input_desc_0 = sim.get_input_desc(0)
3.1.9 get_output_desc#
【Description】
Gets the description of the output of the specified index
【Definition】
get_output_desc(index)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
The index of the output |
【Return value】
MemoryRange
【Example】
output_desc_0 = sim.get_output_desc(0)
3.1.10 get_input_tensor#
【Description】
Gets the RuntimeTensor of the input for the specified index
【Definition】
get_input_tensor(index)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
The index of input tensor |
【Return value】
RuntimeTensor
【Example】
input_tensor_0 = sim.get_input_tensor(0)
3.1.11 set_input_tensor#
【Description】
Sets the RuntimeTensor for the input of the specified index
【Definition】
set_input_tensor(index, tensor)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
Index of input tensor |
tensor |
RuntimeTensor |
Input tensor |
【Return value】
None
【Example】
sim.set_input_tensor(0, nncase.RuntimeTensor.from_numpy(self.inputs[0]['data']))
3.1.12 get_output_tensor#
【Description】
Gets the RuntimeTensor of the output of the specified index
【Definition】
get_output_tensor(index)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
The index of the output tensor |
【Return value】
RuntimeTensor
【Example】
output_arr_0 = sim.get_output_tensor(0).to_numpy()
3.1.13 set_output_tensor#
【Description】
Sets the RuntimeTensor of the output of the specified index
【Definition】
set_output_tensor(index, tensor)
【Parameters】
name |
type |
description |
|---|---|---|
index |
Int |
The index of the output tensor |
tensor |
RuntimeTensor |
Output tensor |
【Return value】
None
【Example】
sim.set_output_tensor(0, tensor)
3.1.14 run#
【Description】
Run kmodel inference
【Definition】
run()
【Parameters】
None
【Return value】
None
【Example】
sim.run()
3.2 Examples#
Preconditions: yolov5s_onnx.py script has compiled the yolov5s.onnx model
yolov5s_onnx_simu.py is located in the /path/to/k230_sdk/src/big/nncase/examples/scripts subdirectory, which is following.
import os
import copy
import argparse
import numpy as np
import onnx
import onnxruntime as ort
import nncase
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def cosine(gt, pred):
return (gt @ pred) / (np.linalg.norm(gt, 2) * np.linalg.norm(pred, 2))
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--model", type=str, help='original model file')
parser.add_argument("--model_input", type=str, help='input bin file for original model')
parser.add_argument("--kmodel", type=str, help='kmodel file')
parser.add_argument("--kmodel_input", type=str, help='input bin file for kmodel')
args = parser.parse_args()
# cpu inference
ort_session = ort.InferenceSession(args.model)
output_names = []
model_outputs = ort_session.get_outputs()
for i in range(len(model_outputs)):
output_names.append(model_outputs[i].name)
model_input = ort_session.get_inputs()[0]
model_input_name = model_input.name
model_input_type = np.float32
model_input_shape = model_input.shape
model_input_data = np.fromfile(args.model_input, model_input_type).reshape(model_input_shape)
cpu_results = []
cpu_results = ort_session.run(output_names, { model_input_name : model_input_data })
# create simulator
sim = nncase.Simulator()
# read kmodel
kmodel = read_model_file(args.kmodel)
# load kmodel
sim.load_model(kmodel)
# read input.bin
# input_tensor=sim.get_input_tensor(0).to_numpy()
dtype = sim.get_input_desc(0).dtype
input = np.fromfile(args.kmodel_input, dtype).reshape([1, 3, 320, 320])
# set input for simulator
sim.set_input_tensor(0, nncase.RuntimeTensor.from_numpy(input))
# simulator inference
nncase_results = []
sim.run()
for i in range(sim.outputs_size):
nncase_result = sim.get_output_tensor(i).to_numpy()
nncase_results.append(copy.deepcopy(nncase_result))
# compare
for i in range(sim.outputs_size):
cos = cosine(np.reshape(nncase_results[i], (-1)), np.reshape(cpu_results[i], (-1)))
print('output {0} cosine similarity : {1}'.format(i, cos))
if __name__ == '__main__':
main()
Execute inference scripts
root@5f718e19f8a7:/mnt/# cd src/big/nncase/examples
root@5f718e19f8a7:/mnt/src/big/nncase/examples # export PATH=$PATH:/usr/local/lib/python3.8/dist-packages/
root@5f718e19f8a7:/mnt/src/big/nncase/examples # python3 scripts/yolov5s_onnx_simu.py --model models/yolov5s.onnx --model_input object_detect/data/input_fp32.bin --kmodel tmp/yolov5s_onnx/test.kmodel --kmodel_input object_detect/data/input_uint8.bin
The comparison of NNcase Simulator and CPU inference results is following.
output 0 cosine similarity : 0.9997244477272034
output 1 cosine similarity : 0.999757707118988
output 2 cosine similarity : 0.9997308850288391
4. KPU runtime APIs (C++)#
4.1 Introduction#
KPU runtime APIs are used to load kmodels, set input data, perform kpu/cpu calculations, and obtain output data on AI devices.
Currently only C++ APIs are available, and the relevant header files and static libraries are located in the /path/to/k230_sdk/src/big/nncase/riscv64 directory.
$ tree -L 3 riscv64/
riscv64/
├── gsl
│ └── gsl-lite.hpp
├── nncase
│ ├── include
│ │ └── nncase
│ └── lib
│ ├── cmake
│ ├── libfunctional_k230.a
│ ├── libnncase.rt_modules.k230.a
│ └── libNncase.Runtime.Native.a
└── rvvlib
├── include
│ ├── k230_math.h
│ ├── nms.h
│ └── rvv_math.h
└── librvv.a
8 directories, 8 files
4.2 APIs#
4.2.1 hrt::create#
【Description】
Create a runtime_tensor
【Definition】
(1) NNCASE_API result<runtime_tensor> create(typecode_t datatype, dims_t shape, memory_pool_t pool = pool_shared_first) noexcept;
(2) NNCASE_API result<runtime_tensor> create(typecode_t datatype, dims_t shape, gsl::span<gsl::byte> data, bool copy,
memory_pool_t pool = pool_shared_first) noexcept;
(3)NNCASE_API result<runtime_tensor>create(typecode_t datatype, dims_t shape, strides_t strides, gsl::span<gsl::byte> data, bool copy, memory_pool_t pool = pool_shared_first, uintptr_t physical_address = 0) noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
datatype |
typecode_t |
Data types, such as dt_float32, dt_uint8, etc |
shape |
dims_t |
The shape of tensor |
data |
gsl::span<gsl::byte> |
User-mode data buffer |
copy |
bool |
Copy or not |
pool |
memory_pool_t |
Memory pool type, default value is pool_shared_first |
physical_address |
uintptr_t |
The user specifies the physical address of the buffer |
【Return value】
result<runtime_tensor>
【Example】
// create input tensor
auto input_desc = interp.input_desc(0);
auto input_shape = interp.input_shape(0);
auto input_tensor = host_runtime_tensor::create(input_desc.datatype, input_shape, hrt::pool_shared).expect("cannot create input tensor");
4.2.2 hrt::sync#
【Description】
Synchronize the cache of tensor.
For the user’s input data, you need to call the sync_write_back of this interface to ensure that the data has been flashed to the DDR.
For the output data after gnne/ai2d calculation, the default gnne/ai2d runtime has been sync_invalidate processed.
【Definition】
NNCASE_API result<void> sync(runtime_tensor &tensor, sync_op_t op, bool force = false) noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
tensor |
runtime_tensor |
The tensor to be manipulated |
on |
sync_op_t |
sync_invalidate (invalidate Tensor’s cache) or sync_write_back (write Tensor’s cache to DDR) |
force |
bool |
Whether it is enforced |
【Return value】
result<void>
【Example】
hrt::sync(input_tensor, sync_op_t::sync_write_back, true).expect("sync write_back failed");
4.2.3 interpreter::load_model#
【Description】
Load the kmodel model
【Definition】
NNCASE_NODISCARD result<void> load_model(gsl::span<const gsl::byte> buffer) noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
buffer |
gsl::span <const gsl::byte> |
kmodel buffer |
【Return value】
result<void>
【Example】
interpreter interp;
auto model = read_binary_file<unsigned char>(kmodel);
interp.load_model({(const gsl::byte *)model.data(), model.size()}).expect("cannot load model.");
4.2.4 interpreter::inputs_size#
【Description】
Gets the number of model inputs
【Definition】
size_t inputs_size() const noexcept;
【Parameters】
None
【Return value】
size_t
【Example】
auto inputs_size = interp.inputs_size();
4.2.5 interpreter::outputs_size#
【Description】
Gets the number of model outputs
【Definition】
size_t outputs_size() const noexcept;
【Parameters】
None
【Return value】
size_t
【Example】
auto outputs_size = interp.outputs_size();
4.2.6 interpreter:: input_shape#
【Description】
Gets the shape of the specified input to the model
【Definition】
const runtime_shape_t &input_shape(size_t index) const noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
index |
size_t |
The index of the input |
【Return value】
runtime_shape_t
【Example】
auto shape = interp.input_shape(0);
4.2.7 interpreter:: output_shape#
【Description】
Gets the shape of the specified output of the model
【Definition】
const runtime_shape_t &output_shape(size_t index) const noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
index |
size_t |
The index of the output |
【Return value】
runtime_shape_t
【Example】
auto shape = interp.output_shape(0);
4.2.8 interpreter:: input_tensor#
【Description】
Gets/sets the input tensor for the specified index
【Definition】
(1) result<runtime_tensor> input_tensor(size_t index) noexcept;
(2) result<void> input_tensor(size_t index, runtime_tensor tensor) noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
index |
size_t |
The index of the input |
tensor |
runtime_tensor |
The runtime tensor of the input |
【Return value】
(1) result<runtime_tensor>
(2) result<void>
```cpp
【示例】
```cpp
// set input
interp.input_tensor(0, input_tensor).expect("cannot set input tensor");
4.2.9 interpreter:: output_tensor#
【Description】
Gets/sets the output tensor of the specified index
【Definition】
(1) result<runtime_tensor> output_tensor(size_t index) noexcept;
(2) result<void> output_tensor(size_t index, runtime_tensor tensor) noexcept;
【Parameters】
name |
type |
description |
|---|---|---|
index |
size_t |
The index of the output |
tensor |
runtime_tensor |
The runtime tensor of the output |
【Return value】
(1) result<runtime_tensor>
(2) result<void>
【Example】
// get output
auto output_tensor = interp.output_tensor(0).expect("cannot get output tensor");
4.2.10 interpreter:: run#
【Description】
Perform kpu calculations
【Definition】
result<void> run() noexcept;
【Parameters】
None
【Return value】
返回result <void>
【Example】
// run
interp.run().expect("error occurred in running model");
4.3 Examples#
#include <chrono>
#include <fstream>
#include <iostream>
#include <nncase/runtime/interpreter.h>
#include <nncase/runtime/runtime_op_utility.h>
#define USE_OPENCV 1
#define preprocess 1
#if USE_OPENCV
#include <opencv2/highgui.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/imgproc.hpp>
#endif
using namespace nncase;
using namespace nncase::runtime;
using namespace nncase::runtime::detail;
#define INTPUT_HEIGHT 224
#define INTPUT_WIDTH 224
#define INTPUT_CHANNELS 3
template <class T>
std::vector<T> read_binary_file(const std::string &file_name)
{
std::ifstream ifs(file_name, std::ios::binary);
ifs.seekg(0, ifs.end);
size_t len = ifs.tellg();
std::vector<T> vec(len / sizeof(T), 0);
ifs.seekg(0, ifs.beg);
ifs.read(reinterpret_cast<char *>(vec.data()), len);
ifs.close();
return vec;
}
void read_binary_file(const char *file_name, char *buffer)
{
std::ifstream ifs(file_name, std::ios::binary);
ifs.seekg(0, ifs.end);
size_t len = ifs.tellg();
ifs.seekg(0, ifs.beg);
ifs.read(buffer, len);
ifs.close();
}
static std::vector<std::string> read_txt_file(const char *file_name)
{
std::vector<std::string> vec;
vec.reserve(1024);
std::ifstream fp(file_name);
std::string label;
while (getline(fp, label))
{
vec.push_back(label);
}
return vec;
}
template<typename T>
static int softmax(const T* src, T* dst, int length)
{
const T alpha = *std::max_element(src, src + length);
T denominator{ 0 };
for (int i = 0; i < length; ++i) {
dst[i] = std::exp(src[i] - alpha);
denominator += dst[i];
}
for (int i = 0; i < length; ++i) {
dst[i] /= denominator;
}
return 0;
}
#if USE_OPENCV
std::vector<uint8_t> hwc2chw(cv::Mat &img)
{
std::vector<uint8_t> vec;
std::vector<cv::Mat> rgbChannels(3);
cv::split(img, rgbChannels);
for (auto i = 0; i < rgbChannels.size(); i++)
{
std::vector<uint8_t> data = std::vector<uint8_t>(rgbChannels[i].reshape(1, 1));
vec.insert(vec.end(), data.begin(), data.end());
}
return vec;
}
#endif
static int inference(const char *kmodel_file, const char *image_file, const char *label_file)
{
// load kmodel
interpreter interp;
auto kmodel = read_binary_file<unsigned char>(kmodel_file);
interp.load_model({ (const gsl::byte *)kmodel.data(), kmodel.size() }).expect("cannot load model.");
// create input tensor
auto input_desc = interp.input_desc(0);
auto input_shape = interp.input_shape(0);
auto input_tensor = host_runtime_tensor::create(input_desc.datatype, input_shape, hrt::pool_shared).expect("cannot create input tensor");
interp.input_tensor(0, input_tensor).expect("cannot set input tensor");
// create output tensor
// auto output_desc = interp.output_desc(0);
// auto output_shape = interp.output_shape(0);
// auto output_tensor = host_runtime_tensor::create(output_desc.datatype, output_shape, hrt::pool_shared).expect("cannot create output tensor");
// interp.output_tensor(0, output_tensor).expect("cannot set output tensor");
// set input data
auto dst = input_tensor.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_write).unwrap().buffer();
#if USE_OPENCV
cv::Mat img = cv::imread(image_file);
cv::resize(img, img, cv::Size(INTPUT_WIDTH, INTPUT_HEIGHT), cv::INTER_NEAREST);
auto input_vec = hwc2chw(img);
memcpy(reinterpret_cast<char *>(dst.data()), input_vec.data(), input_vec.size());
#else
read_binary_file(image_file, reinterpret_cast<char *>(dst.data()));
#endif
hrt::sync(input_tensor, sync_op_t::sync_write_back, true).expect("sync write_back failed");
// run
size_t counter = 1;
auto start = std::chrono::steady_clock::now();
for (size_t c = 0; c < counter; c++)
{
interp.run().expect("error occurred in running model");
}
auto stop = std::chrono::steady_clock::now();
double duration = std::chrono::duration<double, std::milli>(stop - start).count();
std::cout << "interp.run() took: " << duration / counter << " ms" << std::endl;
// get output data
auto output_tensor = interp.output_tensor(0).expect("cannot set output tensor");
dst = output_tensor.impl()->to_host().unwrap()->buffer().as_host().unwrap().map(map_access_::map_read).unwrap().buffer();
float *output_data = reinterpret_cast<float *>(dst.data());
auto out_shape = interp.output_shape(0);
auto size = compute_size(out_shape);
// postprogress softmax by cpu
std::vector<float> softmax_vec(size, 0);
auto buf = softmax_vec.data();
softmax(output_data, buf, size);
auto it = std::max_element(buf, buf + size);
size_t idx = it - buf;
// load label
auto labels = read_txt_file(label_file);
std::cout << "image classify result: " << labels[idx] << "(" << *it << ")" << std::endl;
return 0;
}
int main(int argc, char *argv[])
{
std::cout << "case " << argv[0] << " built at " << __DATE__ << " " << __TIME__ << std::endl;
if (argc != 4)
{
std::cerr << "Usage: " << argv[0] << " <kmodel> <image> <label>" << std::endl;
return -1;
}
int ret = inference(argv[1], argv[2], argv[3]);
if (ret)
{
std::cerr << "inference failed: ret = " << ret << std::endl;
return -2;
}
return 0;
}
5. AI2D runtime APIs (C++)#
5.1 Introduction#
AI2D runtime APIs are used to configure AI2D parameters on AI devices, generate related register configurations, and perform AI2D calculations.
5.1.1 Supported format conversions#
Input format |
Output format |
remark |
|---|---|---|
YUV420_NV12 |
RGB_planar/YUV420_NV12 |
|
YUV420_NV21 |
RGB_planar/YUV420_NV21 |
|
YUV420_I420 |
RGB_planar/YUV420_I420 |
|
YUV400 |
YUV400 |
|
NCHW(RGB_planar) |
NCHW(RGB_planar) |
|
RGB_packed |
RGB_planar/RGB_packed |
|
RAW16 |
RAW16/8 |
Depth map, perform shift operation |
5.1.2 Function Description#
function |
description |
remark |
|---|---|---|
affine transformation |
Support input formats YUV420, YUV400, RGB (planar/packed) Support depth map RAW16 format Support output format YUV400, RGB, depth map |
|
Crop/Resize/Padding |
Support input YUV420, YUV400, RGB Support depth map RAW16 format Resize supports intermediate NCHW arrangement format Support output formats YUV420, YUV400, RGB |
Only the padding constant is supported |
Shift |
Support input format Raw16 Support output format Raw8 |
|
Symbol bits |
Both signed and unsigned input are supported |
5.2 APIs#
5.2.1 ai2d_format#
【Description】
ai2d_format is used to configure input and output data format, which is optional.
【Definition】
enum class ai2d_format
{
YUV420_NV12 = 0,
YUV420_NV21 = 1,
YUV420_I420 = 2,
NCHW_FMT = 3,
RGB_packed = 4,
RAW16 = 5,
}
5.2.2 ai2d_interp_method#
【Description】
ai2d_interp_method is used to configure optional interpolation.
【Definition】
enum class ai2d_interp_method
{
tf_nearest = 0,
tf_bilinear = 1,
cv2_nearest = 2,
cv2_bilinear = 3,
}
5.2.3 ai2d_interp_mode#
【Description】
ai2d_interp_mode is used to configure optional interpolation modes.
【Definition】
enum class ai2d_interp_mode
{
none = 0,
align_corner = 1,
half_pixel = 2,
}
5.2.4 ai2d_pad_mode#
【Description】
ai2d_pad_mode is used to configure padding modes, which is optional. Currently only constant padding is supported.
【Definition】
enum class ai2d_pad_mode
{
constant = 0,
copy = 1,
mirror = 2,
}
5.2.5 ai2d_datatype_t#
【Description】
ai2d_datatype_t is used to set the data type in the AI2D calculation process.
【Definition】
struct ai2d_datatype_t
{
ai2d_format src_format;
ai2d_format dst_format;
datatype_t src_type;
datatype_t dst_type;
ai2d_data_loc src_loc = ai2d_data_loc::ddr;
ai2d_data_loc dst_loc = ai2d_data_loc::ddr;
}
【Parameters】
name |
type |
description |
|---|---|---|
src_format |
ai2d_format |
Input data format |
dst_format |
ai2d_format |
Output data format |
src_type |
datatype_t |
Input data type |
dst_type |
datatype_t |
Output data type |
src_loc |
ai2d_data_loc |
Enter the data location, default DDR |
dst_loc |
ai2d_data_loc |
Output data location, default DDR |
【Example】
ai2d_datatype_t ai2d_dtype { ai2d_format::RAW16, ai2d_format::NCHW_FMT, datatype_t::dt_uint16, datatype_t::dt_uint8 };
5.2.6 ai2d_crop_param_t#
【Description】
ai2d_crop_param_t is used to configure crop-related parameters.
【Definition】
struct ai2d_crop_param_t
{
bool crop_flag = false;
int32_t start_x = 0;
int32_t start_y = 0;
int32_t width = 0;
int32_t height = 0;
}
【Parameters】
name |
type |
description |
|---|---|---|
crop_flag |
bool |
Whether to enable the crop function |
start_x |
Int |
The starting pixel in the width direction |
start_y |
Int |
The starting pixel in the height direction |
width |
Int |
The length of the crop in the width direction |
height |
Int |
The length of the crop in the height direction |
【Example】
ai2d_crop_param_t crop_param { true, 40, 30, 400, 600 };
5.2.7 ai2d_shift_param_t#
【Description】
ai2d_shift_param_t is used to configure shift-related parameters.
【Definition】
struct ai2d_shift_param_t
{
bool shift_flag = false;
int32_t shift_val = 0;
}
【Parameters】
name |
type |
description |
|---|---|---|
shift_flag |
bool |
Whether to enable the shift function |
shift_val |
Int |
The number of bits shifted right |
【Example】
ai2d_shift_param_t shift_param { true, 2 };
5.2.8 ai2d_pad_param_t#
【Description】
ai2d_pad_param_t is used to configure pad-related parameters.
【Definition】
struct ai2d_pad_param_t
{
bool pad_flag = false;
runtime_paddings_t paddings;
ai2d_pad_mode pad_mode = ai2d_pad_mode::constant;
std::vector<int32_t> pad_val; // by channel
}
【Parameters】
name |
type |
description |
|---|---|---|
pad_flag |
bool |
Whether to enable the pad function |
paddings |
runtime_paddings_t |
The padding, shape=, of each dimension, |
pad_mode |
ai2d_pad_mode |
padding模式,只支持constant padding |
pad_val |
std::vector<int32_t> |
The padding value of each channel |
【Example】
ai2d_pad_param_t pad_param { false, { { 0, 0 }, { 0, 0 }, { 0, 0 }, { 60, 60 } }, ai2d_pad_mode::constant, { 255 } };
5.2.9 ai2d_resize_param_t#
【Description】
ai2d_resize_param_t is used to configure resize-related parameters.
【Definition】
struct ai2d_resize_param_t
{
bool resize_flag = false;
ai2d_interp_method interp_method = ai2d_interp_method::tf_bilinear;
ai2d_interp_mode interp_mode = ai2d_interp_mode::none;
}
【Parameters】
name |
type |
description |
|---|---|---|
resize_flag |
bool |
Whether to enable the resize function |
interp_method |
ai2d_interp_method |
The resize interpolation method |
interp_mode |
ai2d_interp_mode |
Resize mode |
【Example】
ai2d_resize_param_t resize_param { true, ai2d_interp_method::tf_bilinear, ai2d_interp_mode::half_pixel };
5.2.10 ai2d_affine_param_t#
【Description】
ai2d_affine_param_t is used to configure affine-related parameters.
【Definition】
struct ai2d_affine_param_t
{
bool affine_flag = false;
ai2d_interp_method interp_method = ai2d_interp_method::cv2_bilinear;
uint32_t cord_round = 0;
uint32_t bound_ind = 0;
int32_t bound_val = 0;
uint32_t bound_smooth = 0;
std::vector<float> M;
}
【Parameters】
name |
type |
description |
|---|---|---|
affine_flag |
bool |
Whether to enable the affine function |
interp_method |
ai2d_interp_method |
The interpolation method employed by Affine |
cord_round |
uint32_t |
Integer bounding 0 or 1 |
bound_ind |
uint32_t |
Boundary pixel mode 0 or 1 |
bound_val |
uint32_t |
Boundary-fill values |
bound_smooth |
uint32_t |
The boundary is smoothed by 0 or 1 |
M |
std::vector<float> |
The vector corresponding to the affine transformation matrix is $Y=[a_0, a_1; a_2, a_3] \cdot X + [b_0, b_1] $, then $ M={a_0,a_1,b_0,a_2,a_3,b_1} $ |
【Example】
ai2d_affine_param_t affine_param { true, ai2d_interp_method::cv2_bilinear, 0, 0, 127, 1, { 0.5, 0.1, 0.0, 0.1, 0.5, 0.0 } };
5.2.11 ai2d_builder:: ai2d_builder#
【Description】
ai2d_builder constructor.
【Definition】
ai2d_builder(dims_t &input_shape, dims_t &output_shape, ai2d_datatype_t ai2d_dtype, ai2d_crop_param_t crop_param, ai2d_shift_param_t shift_param, ai2d_pad_param_t pad_param, ai2d_resize_param_t resize_param, ai2d_affine_param_t affine_param);
【Parameters】
name |
type |
description |
|---|---|---|
input_shape |
dims_t |
Enter a shape |
output_shape |
dims_t |
Output shapes |
ai2d_dtype |
ai2d_datatype_t |
AI2D data type |
crop_param |
ai2d_crop_param_t |
Crop-related parameters |
shift_param |
ai2d_shift_param_t |
shift-related parameters |
pad_param |
ai2d_pad_param_t |
Pad-related parameters |
resize_param |
ai2d_resize_param_t |
resize related parameters |
affine_param |
ai2d_affine_param_t |
Affine related parameters |
【Return value】
None
【Example】
dims_t in_shape { 1, ai2d_input_c_, ai2d_input_h_, ai2d_input_w_ };
auto out_span = ai2d_out_tensor_.shape();
dims_t out_shape { out_span.begin(), out_span.end() };
ai2d_datatype_t ai2d_dtype { ai2d_format::NCHW_FMT, ai2d_format::NCHW_FMT, typecode_t::dt_uint8, typecode_t::dt_uint8 };
ai2d_crop_param_t crop_param { false, 0, 0, 0, 0 };
ai2d_shift_param_t shift_param { false, 0 };
ai2d_pad_param_t pad_param { true, { { 0, 0 }, { 0, 0 }, { 0, 0 }, { 70, 70 } }, ai2d_pad_mode::constant, { 0, 0, 0 } };
ai2d_resize_param_t resize_param { true, ai2d_interp_method::tf_bilinear, ai2d_interp_mode::half_pixel };
ai2d_affine_param_t affine_param { false };
ai2d_builder_.reset(new ai2d_builder(in_shape, out_shape, ai2d_dtype, crop_param, shift_param, pad_param, resize_param, affine_param));
5.2.12 ai2d_builder:: build_schedule#
【Description】
Generate the parameters required for AI2D calculation.
【Definition】
result<void> build_schedule();
【Parameters】
None
【Return value】
result<void>
【Example】
ai2d_builder_->build_schedule();
5.2.13 ai2d_builder:: invoke#
【Description】
Configure the registers and start the calculation of AI2D.
【Definition】
result<void> invoke(runtime_tensor &input, runtime_tensor &output);
【Parameters】
name |
type |
description |
|---|---|---|
input |
runtime_tensor |
Input tensor |
output |
runtime_tensor |
Output tensor |
【Return value】
result<void>
【Example】
// run ai2d
ai2d_builder_->invoke(ai2d_in_tensor, ai2d_out_tensor_).expect("error occurred in ai2d running");
5.3 Examples#
static void test_pad_mini_test(const char *gmodel_file, const char *expect_file)
{
// input tensor
dims_t in_shape { 1, 100, 150, 3 };
auto in_tensor = host_runtime_tensor::create(dt_uint8, in_shape, hrt::pool_shared).expect("cannot create input tensor");
auto mapped_in_buf = std::move(hrt::map(in_tensor, map_access_t::map_write).unwrap());
read_binary_file(gmodel_file, reinterpret_cast<char *>(mapped_in_buf.buffer().data()));
mapped_in_buf.unmap().expect("unmap input tensor failed");
hrt::sync(in_tensor, sync_op_t::sync_write_back, true).expect("write back input failed");
// output tensor
dims_t out_shape { 1, 100, 160, 3 };
auto out_tensor = host_runtime_tensor::create(dt_uint8, out_shape, hrt::pool_shared).expect("cannot create output tensor");
// config ai2d
ai2d_datatype_t ai2d_dtype { ai2d_format::RGB_packed, ai2d_format::RGB_packed, dt_uint8, dt_uint8 };
ai2d_crop_param_t crop_param { false, 0, 0, 0, 0 };
ai2d_shift_param_t shift_param { false, 0 };
ai2d_pad_param_t pad_param { true, { { 0, 0 }, { 0, 0 }, { 0, 0 }, { 10, 0 } }, ai2d_pad_mode::constant, { 255, 10, 5 } };
ai2d_resize_param_t resize_param { false, ai2d_interp_method::tf_bilinear, ai2d_interp_mode::half_pixel };
ai2d_affine_param_t affine_param { false };
// run
ai2d_builder builder { in_shape, out_shape, ai2d_dtype, crop_param, shift_param, pad_param, resize_param, affine_param };
auto start = std::chrono::steady_clock::now();
builder.build_schedule().expect("error occurred in ai2d build_schedule");
builder.invoke(in_tensor, out_tensor).expect("error occurred in ai2d invoke");
auto stop = std::chrono::steady_clock::now();
double duration = std::chrono::duration<double, std::milli>(stop - start).count();
std::cout << "ai2d run: duration = " << duration << " ms, fps = " << 1000 / duration << std::endl;
// compare
auto mapped_out_buf = std::move(hrt::map(out_tensor, map_access_t::map_read).unwrap());
auto actual = mapped_out_buf.buffer().data();
auto expected = read_binary_file<unsigned char>(expect_file);
int ret = memcmp(reinterpret_cast<void *>(actual), reinterpret_cast<void *>(expected.data()), expected.size());
if (!ret)
{
std::cout << "compare output succeed!" << std::endl;
}
else
{
auto cos = cosine(reinterpret_cast<const uint8_t *>(actual), reinterpret_cast<const uint8_t *>(expected.data()), expected.size());
std::cerr << "compare output failed: cosine similarity = " << cos << std::endl;
}
}
5.4 Precautions#
Affine and Resize are mutually exclusive and cannot be turned on at the same time
The input format of the Shift function can only be Raw16
Pad value is configured per channel, and the number of corresponding list elements should be equal to the number of channels
In the current version, when only one function of AI2D is required, other parameters also need to be configured, flag can be set to false, and other fields do not need to be configured.
When multiple functions are configured, the execution order is Crop->Shift->Resize/Affine->Pad, and be careful to match the parameters when configuring them.
6. FAQ#
6.1 xxx.whl is not a supported wheel on this platform. Error is reported when installing wheel package#
Q: ERROR: nncase-1.0.0.20210830-cp37-cp37m-manylinux_2_24_x86_64.whl is not a supported wheel on this platform.
A: Upgrade pip >= 20.3
sudo pip install --upgrade pip
6.2 python: symbol lookup error error is reported when compiling the model#
Q: python: symbol lookup error: /usr/local/lib/python3.8/dist-packages/libnncase.modules.k230.so: undefined symbol: \_ZN6nncase2ir5graph14split_subgraphESt4spanIKPNS0_4nodeELm18446744073709551615EEb error is reported when compiling a model
A: Check whether the nncase and nncase-k230 wheel package versions match
root@a829814d14b7:/mnt/examples# pip list
Package Version
------------ --------------
gmssl 3.2.1
nncase 1.8.0.20220929
nncase-k230 1.9.0.20230403
numpy 1.24.2
Pillow 9.4.0
pip 23.0
pycryptodome 3.17
setuptools 45.2.0
wheel 0.34.2
6.3 std::bad_alloc error is reported when running the inference app on the board#
Q: Run the inference program on the board and throw std::bad_alloc exception
$ ./cpp.sh
case ./yolov3_bfloat16 build at Sep 16 2021 18:12:03
terminate called after throwing an instance of 'std::bad_alloc'
what(): std::bad_alloc
A: std::bad_alloc exception is usually caused by memory allocation failure, you can do the following troubleshooting.
Check if the generated kmodel exceeds the current system available memory
Check whether the app has memory leaks
6.4 data.size_bytes() == size = false (bool) error is reported when running the App inference program on the board#
Q: Run the inference program and throw[..t_runtime_tensor.cpp:310 (create)] data.size_bytes() == size = false (bool) an exception
A: Check the input tensor information of the settings, focusing on whether the input shape and the number of bytes occupied by each element (fp32/uint8) are consistent with the model