CanMV-K230 快速入门指南#
1. CanMV-K230介绍#
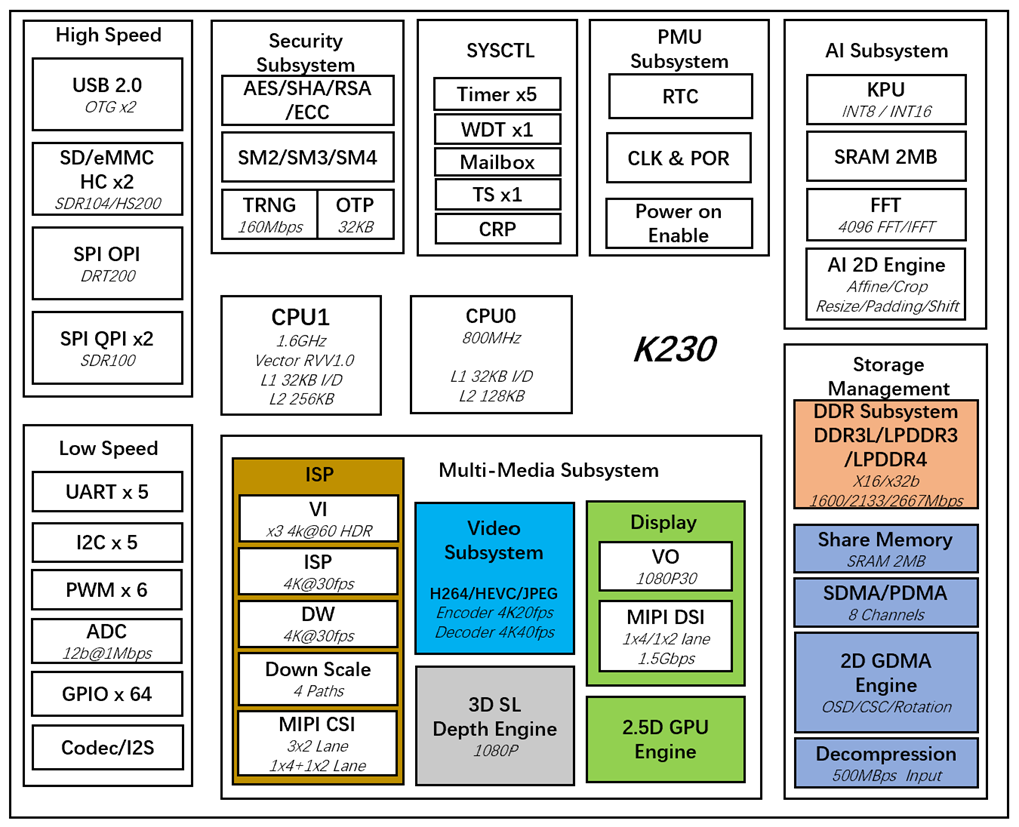
CanMV-K230开发板采用的是嘉楠科技Kendryte®系列AIoT芯片中的最新一代SoC芯片K230。该芯片采用全新的多异构单元加速计算架构,集成了2个RISC-V高能效计算核心,内置新一代KPU(Knowledge Process Unit)智能计算单元,具备多精度AI算力,广泛支持通用的AI计算框架,部分典型网络的利用率超过了70%。
该芯片同时具备丰富多样的外设接口,以及2D、2.5D等多个标量、向量、图形等专用硬件加速单元,可以对多种图像、视频、音频、AI等多样化计算任务进行全流程计算加速,具备低延迟、高性能、低功耗、快速启动、高安全性等多项特性。
2. 快速上手#
2.1 获取开发板#
开发板 |
靓照 |
简介 |
|---|---|---|
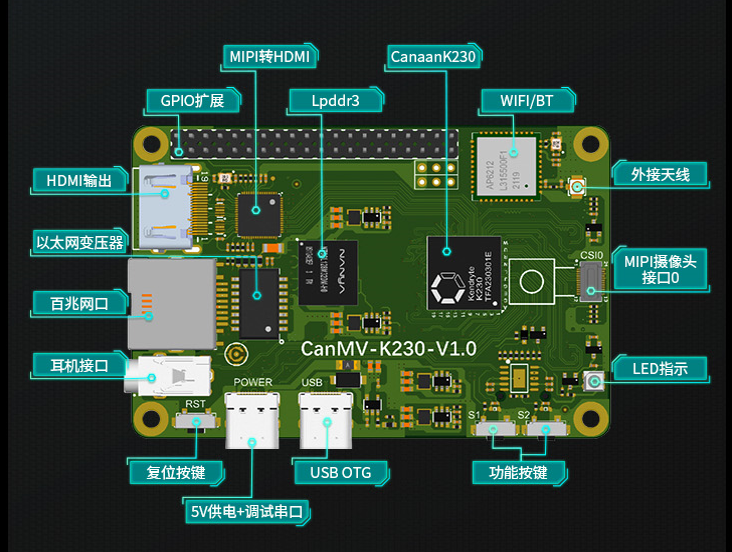
|
基于K230,外置DDR(512MB),内存更大 |
|
TODO |
基于K230D,内置DDR(128MB) |
2.2 烧录固件#
下载对应开发板的固件,参考固件下载指南
2.3 下载IDE#
CanMV-K230支持使用CanMV-IDE进行开发,用户可通过IDE运行代码,并查看运行结果和预览图像
参考IDE下载指南
2.4 运行Demo#
CanMV-K230固件中预置大量Demo程序,用户无需从网络下载即可使用,使用IDE打开虚拟U盘中的示例即可体验
参考运行Demo
3. 摄像头图像预览#
从摄像头获取图像并通过HDMI显示
import time, os, sys
from media.sensor import *
from media.display import *
from media.media import *
sensor = None
try:
print("camera_test")
# construct a Sensor object with default configure
sensor = Sensor()
# sensor reset
sensor.reset()
# set hmirror
# sensor.set_hmirror(False)
# sensor vflip
# sensor.set_vflip(False)
# set chn0 output size, 1920x1080
sensor.set_framesize(Sensor.FHD)
# set chn0 output format
sensor.set_pixformat(Sensor.YUV420SP)
# bind sensor chn0 to display layer video 1
bind_info = sensor.bind_info()
Display.bind_layer(**bind_info, layer = Display.LAYER_VIDEO1)
# use hdmi as display output
Display.init(Display.LT9611, to_ide = True, osd_num = 2)
# init media manager
MediaManager.init()
# sensor start run
sensor.run()
while True:
os.exitpoint()
except KeyboardInterrupt as e:
print("user stop: ", e)
except BaseException as e:
print(f"Exception {e}")
finally:
# sensor stop run
if isinstance(sensor, Sensor):
sensor.stop()
# deinit display
Display.deinit()
os.exitpoint(os.EXITPOINT_ENABLE_SLEEP)
time.sleep_ms(100)
# release media buffer
MediaManager.deinit()
4. AI Demo#
人脸检测demo
from libs.PipeLine import PipeLine, ScopedTiming
from libs.AIBase import AIBase
from libs.AI2D import Ai2d
import os
import ujson
from media.media import *
from time import *
import nncase_runtime as nn
import ulab.numpy as np
import time
import utime
import image
import random
import gc
import sys
import aidemo
# 自定义人脸检测类,继承自AIBase基类
class FaceDetectionApp(AIBase):
def __init__(self, kmodel_path, model_input_size, anchors, confidence_threshold=0.5, nms_threshold=0.2, rgb888p_size=[224,224], display_size=[1920,1080], debug_mode=0):
super().__init__(kmodel_path, model_input_size, rgb888p_size, debug_mode) # 调用基类的构造函数
self.kmodel_path = kmodel_path # 模型文件路径
self.model_input_size = model_input_size # 模型输入分辨率
self.confidence_threshold = confidence_threshold # 置信度阈值
self.nms_threshold = nms_threshold # NMS(非极大值抑制)阈值
self.anchors = anchors # 锚点数据,用于目标检测
self.rgb888p_size = [ALIGN_UP(rgb888p_size[0], 16), rgb888p_size[1]] # sensor给到AI的图像分辨率,并对宽度进行16的对齐
self.display_size = [ALIGN_UP(display_size[0], 16), display_size[1]] # 显示分辨率,并对宽度进行16的对齐
self.debug_mode = debug_mode # 是否开启调试模式
self.ai2d = Ai2d(debug_mode) # 实例化Ai2d,用于实现模型预处理
self.ai2d.set_ai2d_dtype(nn.ai2d_format.NCHW_FMT, nn.ai2d_format.NCHW_FMT, np.uint8, np.uint8) # 设置Ai2d的输入输出格式和类型
# 配置预处理操作,这里使用了pad和resize,Ai2d支持crop/shift/pad/resize/affine,具体代码请打开/sdcard/app/libs/AI2D.py查看
def config_preprocess(self, input_image_size=None):
with ScopedTiming("set preprocess config", self.debug_mode > 0): # 计时器,如果debug_mode大于0则开启
ai2d_input_size = input_image_size if input_image_size else self.rgb888p_size # 初始化ai2d预处理配置,默认为sensor给到AI的尺寸,可以通过设置input_image_size自行修改输入尺寸
top, bottom, left, right = self.get_padding_param() # 获取padding参数
self.ai2d.pad([0, 0, 0, 0, top, bottom, left, right], 0, [104, 117, 123]) # 填充边缘
self.ai2d.resize(nn.interp_method.tf_bilinear, nn.interp_mode.half_pixel) # 缩放图像
self.ai2d.build([1,3,ai2d_input_size[1],ai2d_input_size[0]],[1,3,self.model_input_size[1],self.model_input_size[0]]) # 构建预处理流程
# 自定义当前任务的后处理,results是模型输出array列表,这里使用了aidemo库的face_det_post_process接口
def postprocess(self, results):
with ScopedTiming("postprocess", self.debug_mode > 0):
post_ret = aidemo.face_det_post_process(self.confidence_threshold, self.nms_threshold, self.model_input_size[1], self.anchors, self.rgb888p_size, results)
if len(post_ret) == 0:
return post_ret
else:
return post_ret[0]
# 绘制检测结果到画面上
def draw_result(self, pl, dets):
with ScopedTiming("display_draw", self.debug_mode > 0):
if dets:
pl.osd_img.clear() # 清除OSD图像
for det in dets:
# 将检测框的坐标转换为显示分辨率下的坐标
x, y, w, h = map(lambda x: int(round(x, 0)), det[:4])
x = x * self.display_size[0] // self.rgb888p_size[0]
y = y * self.display_size[1] // self.rgb888p_size[1]
w = w * self.display_size[0] // self.rgb888p_size[0]
h = h * self.display_size[1] // self.rgb888p_size[1]
pl.osd_img.draw_rectangle(x, y, w, h, color=(255, 255, 0, 255), thickness=2) # 绘制矩形框
else:
pl.osd_img.clear()
# 获取padding参数
def get_padding_param(self):
dst_w = self.model_input_size[0] # 模型输入宽度
dst_h = self.model_input_size[1] # 模型输入高度
ratio_w = dst_w / self.rgb888p_size[0] # 宽度缩放比例
ratio_h = dst_h / self.rgb888p_size[1] # 高度缩放比例
ratio = min(ratio_w, ratio_h) # 取较小的缩放比例
new_w = int(ratio * self.rgb888p_size[0]) # 新宽度
new_h = int(ratio * self.rgb888p_size[1]) # 新高度
dw = (dst_w - new_w) / 2 # 宽度差
dh = (dst_h - new_h) / 2 # 高度差
top = int(round(0))
bottom = int(round(dh * 2 + 0.1))
left = int(round(0))
right = int(round(dw * 2 - 0.1))
return top, bottom, left, right
if __name__ == "__main__":
# 显示模式,默认"hdmi",可以选择"hdmi"和"lcd"
display_mode="hdmi"
if display_mode=="hdmi":
display_size=[1920,1080]
else:
display_size=[800,480]
# 设置模型路径和其他参数
kmodel_path = "/sdcard/app/tests/kmodel/face_detection_320.kmodel"
# 其它参数
confidence_threshold = 0.5
nms_threshold = 0.2
anchor_len = 4200
det_dim = 4
anchors_path = "/sdcard/app/tests/utils/prior_data_320.bin"
anchors = np.fromfile(anchors_path, dtype=np.float)
anchors = anchors.reshape((anchor_len, det_dim))
rgb888p_size = [1920, 1080]
# 初始化PipeLine,用于图像处理流程
pl = PipeLine(rgb888p_size=rgb888p_size, display_size=display_size, display_mode=display_mode)
pl.create() # 创建PipeLine实例
# 初始化自定义人脸检测实例
face_det = FaceDetectionApp(kmodel_path, model_input_size=[320, 320], anchors=anchors, confidence_threshold=confidence_threshold, nms_threshold=nms_threshold, rgb888p_size=rgb888p_size, display_size=display_size, debug_mode=0)
face_det.config_preprocess() # 配置预处理
try:
while True:
os.exitpoint() # 检查是否有退出信号
with ScopedTiming("total",1):
img = pl.get_frame() # 获取当前帧数据
res = face_det.run(img) # 推理当前帧
face_det.draw_result(pl, res) # 绘制结果
pl.show_image() # 显示结果
gc.collect() # 垃圾回收
except Exception as e:
sys.print_exception(e) # 打印异常信息
finally:
face_det.deinit() # 反初始化
pl.destroy() # 销毁PipeLine实例